Sierra’s 𝜏-bench is shaping the development and evaluation of agents
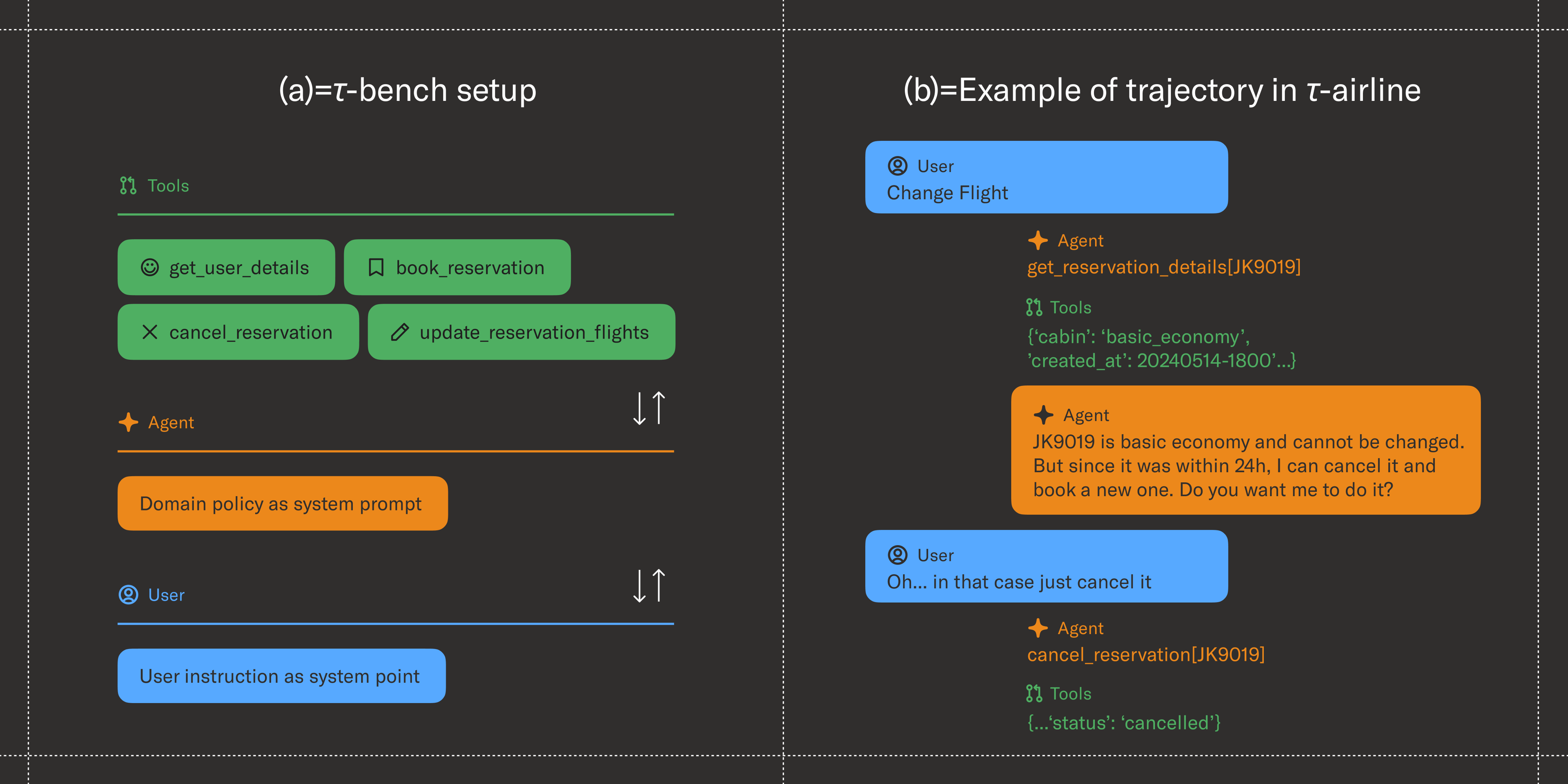
The reliability of AI agents in navigating real-world challenges is key to their effectiveness. It’s why Sierra’s research team developed 𝜏-bench (tool-agent-user benchmark) in June 2024. Unlike traditional benchmarks, 𝜏-bench doesn’t just test whether an agent can complete a task once; it measures whether it can do so consistently multiple times. A detailed description of 𝜏-bench is available in our paper on arXiv, and you can access the benchmark on GitHub.
Early results showed that even state-of-the-art agents, such as those based on GPT-4, succeeded in fewer than 50% of tasks and struggled with consistency—achieving only ~25% success when repeating the same task eight times. This underscores why benchmarks like 𝜏-bench are critical: they expose weaknesses in AI reasoning, tool use, and reliability that one-time evaluations fail to capture.
In this post, we explore how Sierra’s 𝜏-bench is shaping the development and evaluation of agents—from academic research to industry applications and next-generation development.
Impact of 𝜏-bench on agent evaluation in research
In less than a year, 𝜏-bench has become a cornerstone of AI agent evaluation, cited in academic research as a critical step toward more realistic, multi-turn agent benchmarking, and inspiring new domain-specific agent evaluation frameworks.
Expanding agent evaluation to new domains
MedAgentBench introduces a specialized medical domain benchmark that explicitly cites 𝜏-Bench as an exemplar of general agent evaluation. The authors observed that while benchmarks like 𝜏-bench effectively test general agent capabilities, there was no standardized medical agent benchmark available, which prompted them to create a realistic EMR (electronic medical record) environment for clinical tasks. MedAgentBench expands on 𝜏-bench's approach by providing hospital tools like FHIR APIs and databases, along with physician-written scenarios, successfully bringing the tool-agent-user paradigm to healthcare applications.
The LAM Simulator (Anonymous, ICLR 2025) proposes a "Large Action Model Simulator" framework for training and evaluating agents, positioning itself relative to 𝜏-bench in the research landscape. While LAM Simulator's authors praise 𝜏-bench's multi-turn tool-using setup, they note its limited coverage of only two domains (retail and airline).
To address this limitation, they developed an environment supporting larger-scale, diverse tool usage and real-time interactions. In their comprehensive comparison of agent benchmarks, they list 𝜏-bench alongside other notable frameworks like WebShop, WebArena, and AgentBench, aiming to address 𝜏-bench's constraints by supporting a broader range of domains and continuous feedback mechanisms.
𝜏-bench’s role in benchmarking trends
Beyond specific implementations, 𝜏-bench features prominently in benchmark surveys and analyses. A comprehensive Berkeley report on LLM training cites 𝜏-bench as a novel benchmark that tests real-world tool-use and user interaction capabilities. Other academic commentary positions 𝜏-bench (alongside contemporaries like SWE-Bench for coding) as representing a new class of rigorous agent benchmarks focused on multi-step reasoning and rule-following behaviors.
Impact of 𝜏-bench on agent evaluation in industry
Beyond academia, 𝜏-bench has become a critical benchmark in the AI industry, shaping how companies assess and improve their agents. AI labs and startups now rely on it to measure real-world performance, proving its impact extends far beyond research papers.
Anthropic’s adoption of 𝜏-bench
Anthropic has notably embraced 𝜏-bench as a key benchmark to demonstrate advances in their Claude models. In late 2024, Anthropic announced that Claude 3.5 Sonnet achieved state-of-the-art results on 𝜏-bench, significantly outperforming earlier models.
They also reported substantial improvements with Claude 3.5, and, more recently, introduced Claude 3.7 as the new top performer on τ-bench, reflecting the company's strategic focus on tool-use and multi-turn interaction as critical evaluation metrics. Notably, Anthropic's model cards now discuss the pass^k reliability metric (introduced by 𝜏-bench) to measure consistency across multiple trials, showing how 𝜏-bench's methodology has influenced internal evaluation practices.
Wider industry adoption
AI startups focused on agent technologies have also adopted 𝜏-bench for evaluation purposes—Scaled Cognition recently used the benchmark to evaluate their agent foundation models.
Applications of 𝜏-bench
𝜏-bench has driven major advancements in AI agent capabilities, particularly in reinforcement learning, decision-making, and long-horizon planning for multi-turn interactions. Researchers and industry leaders are using it to develop more reliable, adaptable, and goal-oriented agents.
Improving reliability and consistency
The introduction of the pass^k metric in 𝜏-bench, which measures an agent's probability of success across k repeated runs, has shifted research focus toward reliability and consistency. Researchers are now exploring training methods to increase consistency, such as using reinforcement learning or self-correction loops to reduce failure rates on retries.
Anthropic's team noted that 𝜏-bench's pass^k metric exposed how even strong models degrade over multiple attempts, prompting them to incorporate self-reflection and longer "chain-of-thought" prompting (Claude's extended thinking mode) to boost consistent success. This approach parallels reinforcement learning techniques where agents are encouraged to plan more cautiously or verify steps to ensure all attempts succeed. τ-bench's influence is evident in how new models are being tuned not just for one-shot accuracy but for robustness over repeated trials.
Better planning and tool-use strategies
𝜏-bench tasks demand long-horizon planning, such as booking flights through multiple dialogue turns and API calls. Its findings revealed that naive ReAct-style agents often break down during these complex sequences.
In response, researchers are developing enhanced planning algorithms. Some work proposes hierarchical or cognitive architectures (as suggested by Sierra's team) to help agents maintain goals and memory throughout conversations. Others, like the LAM Simulator project, focus on training agents via self-exploration in simulated worlds to improve their tool-use policies. These efforts aim to address the key failure modes 𝜏-bench revealed: following written policies more strictly, handling ambiguous user input, and recovering from errors mid-task.
Early R&D results are promising. For instance, Anthropic's minimal "SWE-Agent" scaffold—developed for coding tasks—was adapted to 𝜏-bench and helped Claude 3.5 achieve high scores without heavy prompt engineering. This suggests that streamlined agent loops (perceive, act, reflect) combined with powerful models can yield better decision-making under 𝜏-bench evaluation.
Domain-specific agent training
𝜏-bench's framework of simulated “user + tools + rules” is being applied to new domains in research. MedAgentBench has applied 𝜏-bench's ideas for clinical assistants, and similar efforts are emerging in legal AI (e.g., LegalAgentBench for courtroom or contract analysis) that build custom tool suites for agents.
While these works are still developing, they credit benchmarks like 𝜏-bench for providing a template on how to rigorously test agents that must both converse and take actions under constraints. By establishing concrete success metrics—such as whether the agent changed the database to the correct end-state—researchers can apply reinforcement learning or planning algorithms and directly measure improvements in task completion, not just dialogue quality.
Performance trends on 𝜏-bench
The overall trend on 𝜏-bench shows that model performance is steadily improving, but there remains substantial room for advancement. From initial success rates below 50%, the best models are now crossing 80% pass^1 in the easier domain (retail). However, even the most capable agents still fail on several tasks and struggle with consistent reliability across multiple runs.
Reliability challenges and the pass^k metric
The pass^k curves remain far from ideal—the initial paper demonstrated that all models' performance "degrades as k increases" (e.g. solid drop by k=8). This indicates that achieving consistent success over repeated attempts remains a significant challenge. It's likely that new techniques, such as improved user simulation during training or specialized fine-tuning on multi-turn tasks, will be necessary for any model to approach near-perfect performance on 𝜏-bench.
The competitive race for higher 𝜏-bench scores
This unsolved gap in reliability represents one of 𝜏-bench's key values: it will continue to serve as a meaningful benchmark where progress can be measured over time. We can anticipate a competitive leaderboard race among AI labs—similar to what has occurred with other benchmarks—where successive model iterations (GPT-5, Claude 4, etc.) will likely tout higher 𝜏-bench scores, until eventually human-level or rule-perfect performance comes within reach.
In the meantime, 𝜏-bench's inclusion in public model comparisons ensures that researchers and developers maintain focus on both raw intelligence and an agent's practical ability to follow instructions throughout a dialogue. This dual emphasis will guide the AI community's priorities toward building agents that are not only intellectually capable but also effective and reliable in real-world, interactive scenarios.
Help improve 𝜏-bench
The rapid adoption and broad impact of 𝜏-bench across academic research, industry benchmarking, and R&D applications demonstrate its value as a standardized framework for evaluating AI agent capabilities. As performance trends show steady improvement while highlighting remaining challenges, 𝜏-bench continues to drive innovation toward more reliable and effective AI assistants.
Given how broadly 𝜏-bench is used, we wanted to have an open call for improvements. If you have suggestions for enhancing the benchmark or ideas for expanding its application to new domains, please email research@sierra.ai. Your contributions will help shape the future development of AI agent evaluation.