Engineering low-latency voice agents
A few seconds of silence can break the rhythm of an entire conversation. And with agents, timing defines reality — short delays feel human, long ones feel robotic.
This post breaks down how we’ve worked to engineer latency out of Sierra’s voice stack: from detecting the end of a customer’s speech to streaming a response that feels instantaneous.
Measuring latency where it matters
The most important latency metric for conversational AI systems is Time to First Audio (TTFA) — how long it takes for the agent to start speaking after the customer finishes. Some systems “game” this with filler audio (“uh-huh,” “let me check”), but we measure time to the first relevant response — when the agent genuinely begins to answer.
People start to disengage after a brief “silence window.” So our goal is to stay well within that threshold: fast enough to feel responsive, long enough to say something meaningful.
The latency stack
Every conversational turn moves through three latency-critical hops:
- End-of-speech detection (Transcription)
- Runtime reasoning (Agent + LLM)
- Speech synthesis (Text-to-speech)
Sierra’s voice architecture supports combining steps (for instance with voice-to-voice models), but enterprise workflows usually demand too much reliability, capability, and observability. As we sometimes joke, you still can’t make an API call to a system of record with voice tokens.
1. End-of-speech detection
Real-world audio is messy — background noise, cross-talk, variable microphone quality. The hardest problem is knowing when someone has finished speaking. Trigger your agent too early and you interrupt the customer; too late and you add dead air.
We trained a custom voice activity detection (VAD) model optimized for noisy, multi-speaker environments. It predicts speech completion earlier and more accurately than off-the-shelf alternatives, cutting reaction lag by hundreds of milliseconds.
This also makes our metrics more precise: TTFA is measured from the true “end of user speech”, not from delayed or approximate timestamps.
2. Runtime reasoning
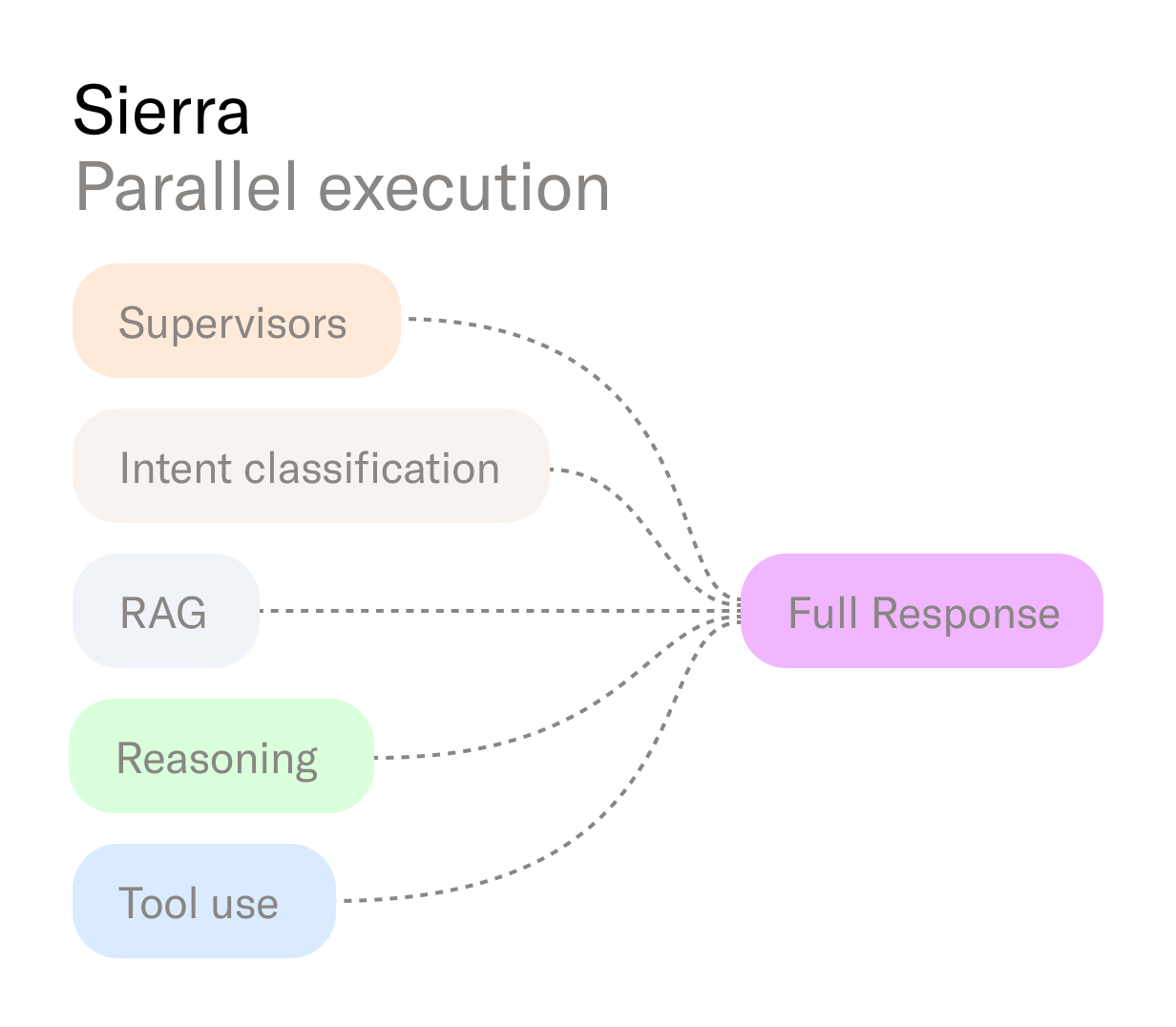
Most latency accrues in the agent and model runtime — the point where speech becomes thought. We rebuilt this stage as a concurrent graph, not a sequential pipeline.
- Parallel execution. Independent tasks — abuse detection, retrieval, API calls — run in parallel, synchronizing only when dependencies require it.
- Predictive prefetching. The runtime precomputes the likely next steps. When a known customer calls, their order data loads immediately so “Where’s my package?” can be answered instantly.
- Adaptive model selection. Tasks are routed to models based on complexity and cost. Small, fast models handle summarization or state updates; larger models handle deep reasoning.
- Provider hedging. Requests are fanned out to multiple model providers, and the fastest valid response wins. This minimizes tail latency and shields against transient slowdowns.
- Progress indicators. When reasoning takes longer, context-aware interim responses like “Let me pull up your order details” keep callers engaged while the full response completes.
3. Speech synthesis
Turning text into speech is the final hop — and a common latency trap. We reduced synthesis time through three core techniques.
- Caching. Frequent phrases such as greetings and confirmations can be precomputed, cutting playback latency to zero.
- Streaming. Audio begins playback as soon as the first tokens arrive, rather than waiting for the full synthesis to complete.
- Batching. For non-streaming providers, responses are delivered sentence by sentence so users hear speech almost immediately.
These techniques preserve conversational rhythm — the agent sounds fluid, not staged.
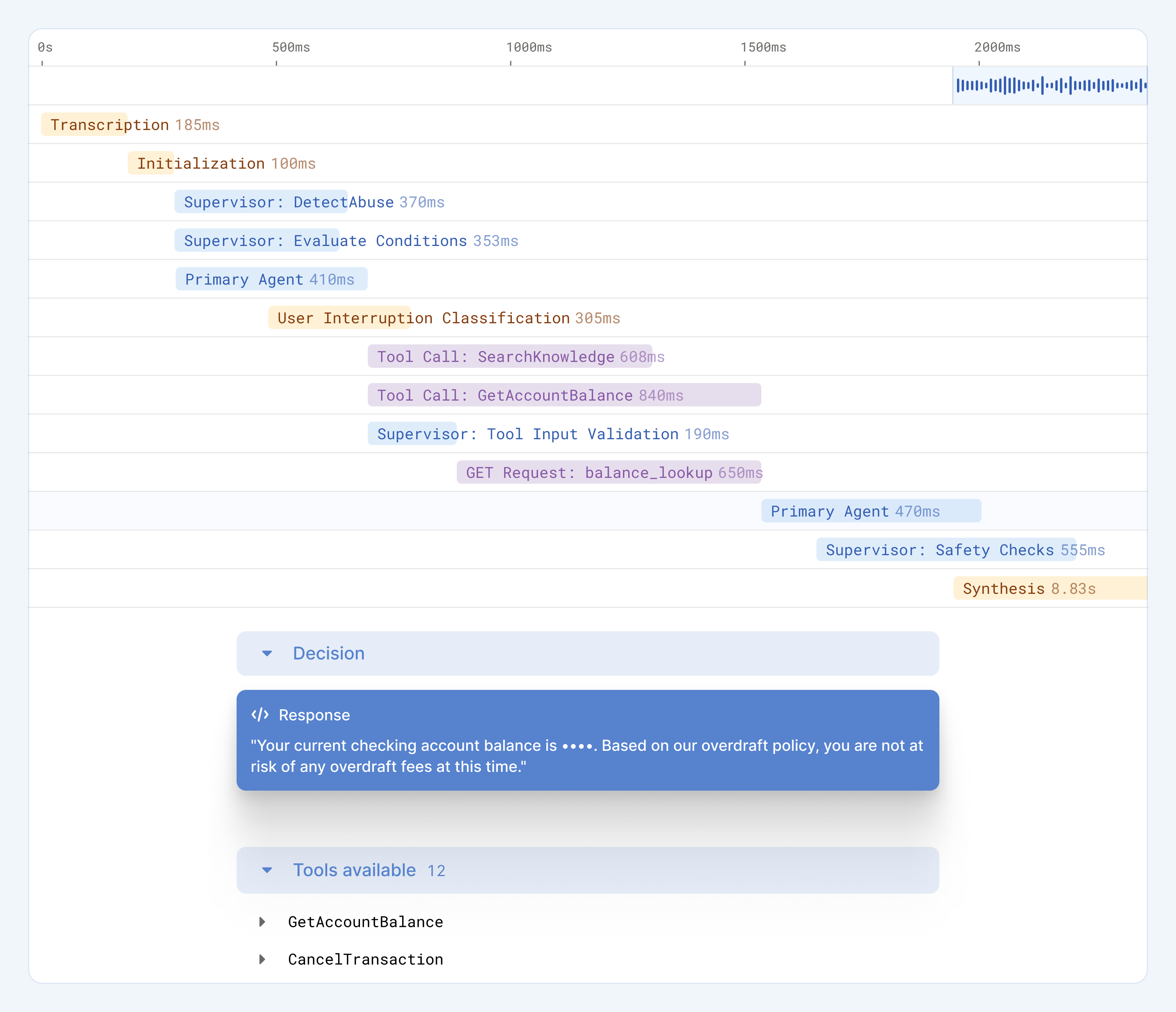
Observability
You can’t optimize what you can’t see. Every stage of the voice stack emits agent traces that expose timing breakdowns across transcription, reasoning, and synthesis. Developers can see where milliseconds are lost — and reclaim them through caching, concurrency, or deferred execution.
This instrumentation also lets us compare model providers, measure regressions, and visualize the effects of each optimization over time. Latency isn’t an abstract metric; it’s an observable, measurable engineering property.
The bigger picture
Better conversations happen in real time. Milliseconds decide whether an interaction feels alive or artificial. We treat those milliseconds like gold — because every one saved makes a voice agent not just sound smarter, but feel more human. And on customer calls, silence is never golden.