A more reliable inference layer for foundation models
When your favorite foundation model provider goes down, your AI agent stops working. When they're having a slow day, your customers wait.
This is the harsh reality of building on top of foundation models today. Foundation models are still less reliable than traditional web services, with more downtime and response times measured in seconds, not milliseconds. And as adoption grows, they’re accessed through a burgeoning ecosystem of providers and applications, which have similar functionality but different levels of reliability.
Last year, we turned this bug into a feature—developing an adaptive routing client that dynamically selects providers to maximize uptime, minimize latency, and improve the overall experience.
Sierra’s adaptive routing client
Sierra treats foundation model reliability as a dynamic optimization problem. Our adaptive routing client evaluates providers using real-time data, routing foundation model API requests from our agents to the highest performers, and additionally hedges a parallel request for responses that haven’t come back as quickly as we’d like.
Together, these approaches have enabled Sierra to avoid downtime during multiple provider outages and reduce P99 latencies by more than 70%. I’ll share a bit about our intelligent routing and hedging strategies, and how they are architected to deliver real-world resilience and improved performance.
Health and performance-based traffic routing
Our first strategy—health and performance-based traffic routing—seeks to answer this basic question: which provider is most likely to handle this request successfully and quickly right now? To get the answer just right, we’ve designed a few key system features that I’ll highlight below.
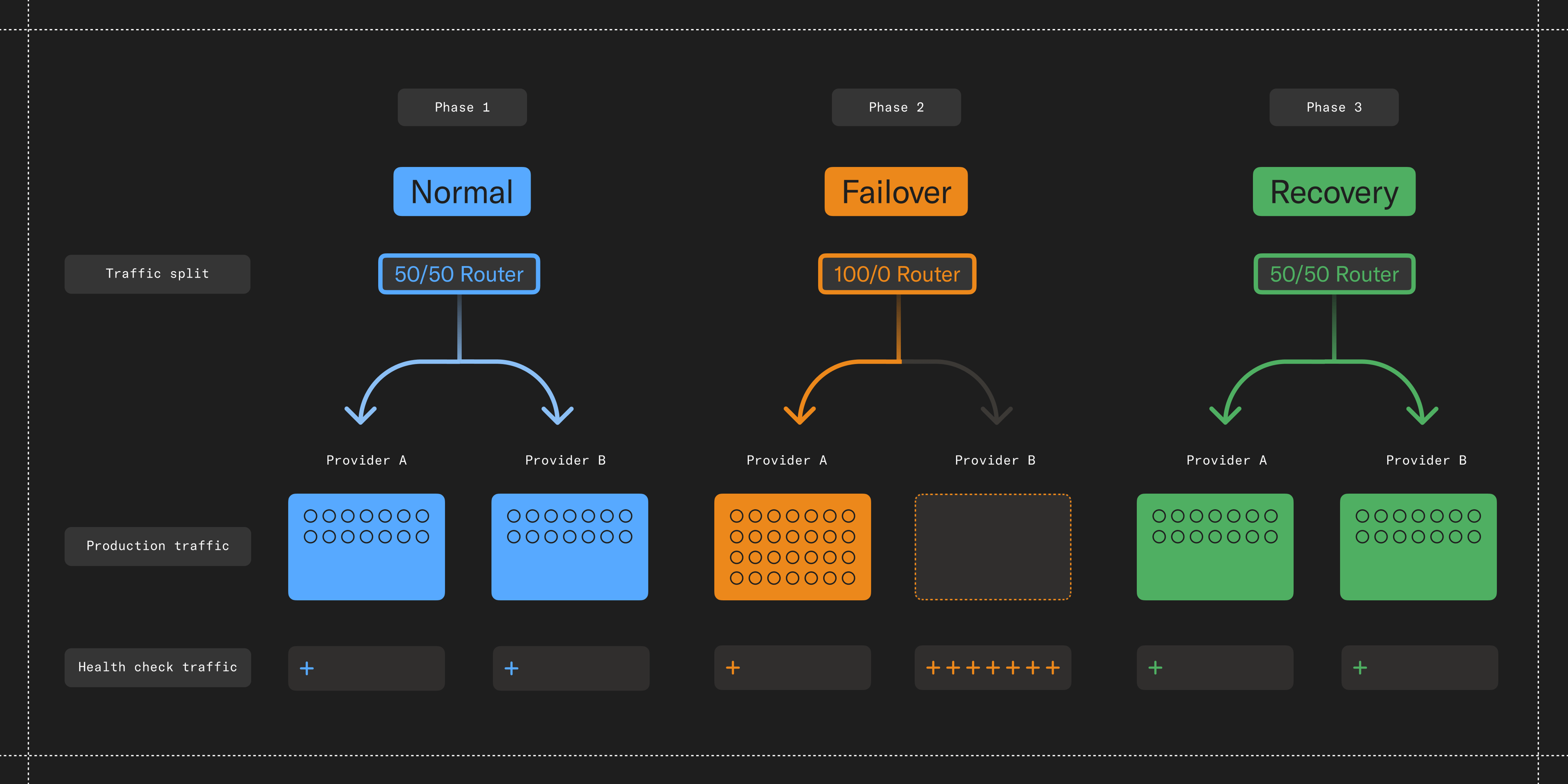
Health-driven steering modes
In designing our routing system, we quickly learned that while reliability and speed both matter, reliability comes first—a fast failure is still a failure. Only when providers are healthy do we then optimize for secondary characteristics like speed! We codified this preference by designating two operating modes in our router: Balanced and Protective.
In Balanced Mode, when all providers are performing well, traffic is distributed using a composite of success rates and latency to optimize for speed and reliability.
In Protective Mode, when one provider is struggling, we shift all our traffic to the best performing one—maximizing our agent’s chances of successfully completing an API call. This combination ensures high performance when everything is going well, and resilience during disruptions.
The impact has been meaningful. During our rollout month, we received multiple outage notifications, including one lasting several hours. But despite these disruptions, customers experienced no downtime as the system seamlessly rerouted traffic and then rebalanced it when the impacted providers had recovered.
Adaptive health checks
When we shift traffic away from a provider experiencing issues, we get less performance data on them—which creates the risk we don’t turn that provider back on quickly once their issue is resolved.
To solve this challenge, we built an adaptive sampling system, which adjusts non-production health check frequency in real-time. Each measurement window enforces a minimum number of data points to ensure statistical confidence. When production traffic drops due to routing changes, the system increases dedicated health checks, then scales them back as normal traffic resumes—ensuring it has the data it needs in every window to make good decisions about when to shift traffic back and forth.
Weighted tumbling windows
Another hard challenge has been balancing responsiveness with stability—the need for the system to react quickly enough to protect customers from poor-quality service, but not so aggressively as to waste time switching providers during brief anomalies in performance.
The solution: tumbling measurement windows with asymmetric historical weighting based on an Exponentially Weighted Moving Average (EWMA).
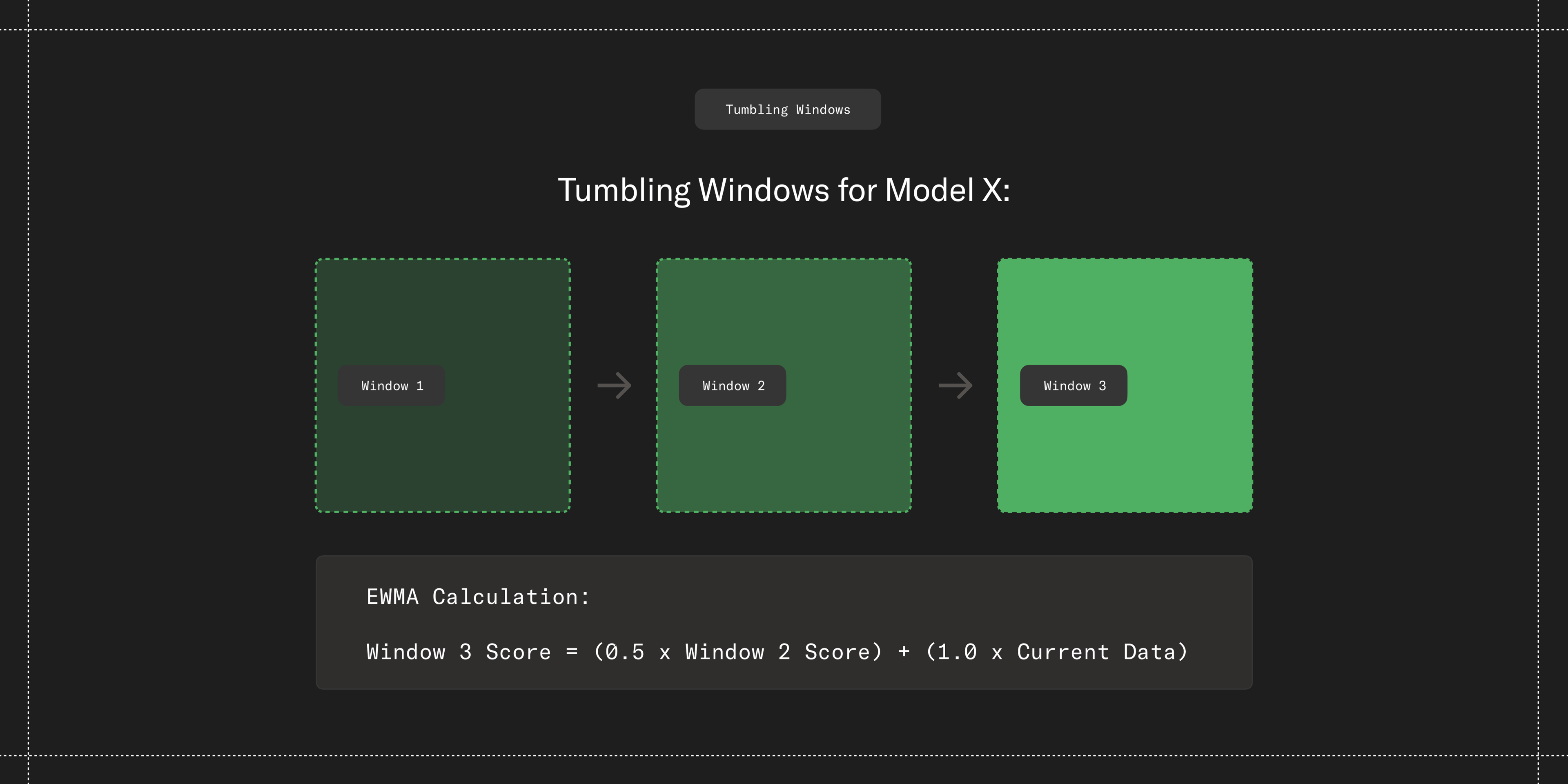
This approach applies established time-series analysis to our reliability needs, which has proven effective at distinguishing between transient anomalies and real performance issues. In one incident, a provider briefly recovered before failing again, and our algorithm adjusted traffic both ways with no impact on availability, a scenario that would have challenged simpler systems.
Request hedging for tail latency optimization
While our routing system maximizes success rates and generally favors the faster provider, we still face the challenge of tail latency—those few slow requests that significantly impact unlucky customers. Even when providers perform well overall, some requests can take unusually long due to factors beyond our control, and possibly even theirs.
To address this, we added request hedging, which sends a backup request only if the initial one exceeds a set latency threshold. This avoids full duplication while minimizing worst-case delays.
The results here have been dramatic. Our P99 latency (the slowest 1% of requests) dropped by over 70%, turning multi-second delays into real-time responses. These improvements are especially noticeable when providers are having performance issues and latency would otherwise spike significantly.
Engineering principles for building reliable and performant AI systems
Building reliable AI systems requires applying rigorous engineering principles to novel technical domains. Our experience has reinforced several foundational tenets:
- Measure everything: Drive good decision-making through comprehensive observability across providers.
- Adapt real-time: Design for responsiveness to changing conditions.
- Control adaptation: Balance responsiveness with stable routing through the use of weights.
- Hedge strategically: Shorten the long tail by issuing parallel requests in statistically informed ways.
The future of AI deployment depends not only on model capabilities but the reliability, resilience, and speed of the systems delivering them. Sierra’s adaptive routing work is one component in the broader reliability engineering framework, which is essential to making the promise of AI real.
If you're excited to define reliability for the AI era—building the routing layers, failover logic, and observability tools that keep agents online—we’re hiring.