Confidence in every conversation
When companies put an AI agent in front of customers, it’s representing their brand publicly, and that’s a high bar. Even the most capable language models make mistakes, and at scale one off-brand or inaccurate answer can ripple quickly across your entire customer experience.
At Sierra, we’ve found that the solution to many AI problems is, in fact, more AI. So rather than relying on manual checks or static rules, we use AI supervisors and monitors to make agents dependable — correcting them in real time, and continuously evaluating the quality of every conversation.
Supervisors: real-time correction
Supervisors are in-the-moment guardrails — a Jiminy Cricket for each agent that sits on its “shoulder” and keeps it honest. Supervisors run in parallel, reviewing each response as it’s generated, verifying facts, enforcing policy, and redirecting conversations that start going off the rails, instantly stepping in to get them back on track, or escalating to a human when needed.
In addition to accuracy, supervisors work to protect brands and build customer trust, helping agents navigate nuance; handle sensitive topics with care; keep conversations focused; and maintain the right tone. This oversight ensures that even when faced with hard-to-predict questions and different ways of phrasing them, agents behave predictably — giving businesses the confidence to go live with their agents quickly.
Monitors: always-on evaluation
Supervisors keep each interaction on track in real time. But performance is about more than single exchanges. Brands need to understand what’s happening across thousands of customer conversations every day.
Traditionally, teams often relied on spot checks or keyword triggers to gauge quality and customer sentiment. But it’s a slow, manual process that by its nature only touches a fraction of the conversations that happen every day, and which can often miss the nuances that are so important to get right: tone, empathy, or coherence.
Monitors turn that approach on its head, reviewing every conversation, automatically — and flagging the ones that need attention. This gives teams a complete picture of how their agents are performing and customers are responding. It’s the unfiltered truth, versus simply a snapshot in time.
Out of the box, agents built on Sierra are evaluated across four key attributes:
- Their coherence — do they have a clear, logical flow?
- Their repetitiveness — do they avoid circular or redundant responses?
- Their grounding in fact — do they stick to verified knowledge?
- Their sentiment — do they have the right tone and emotion?
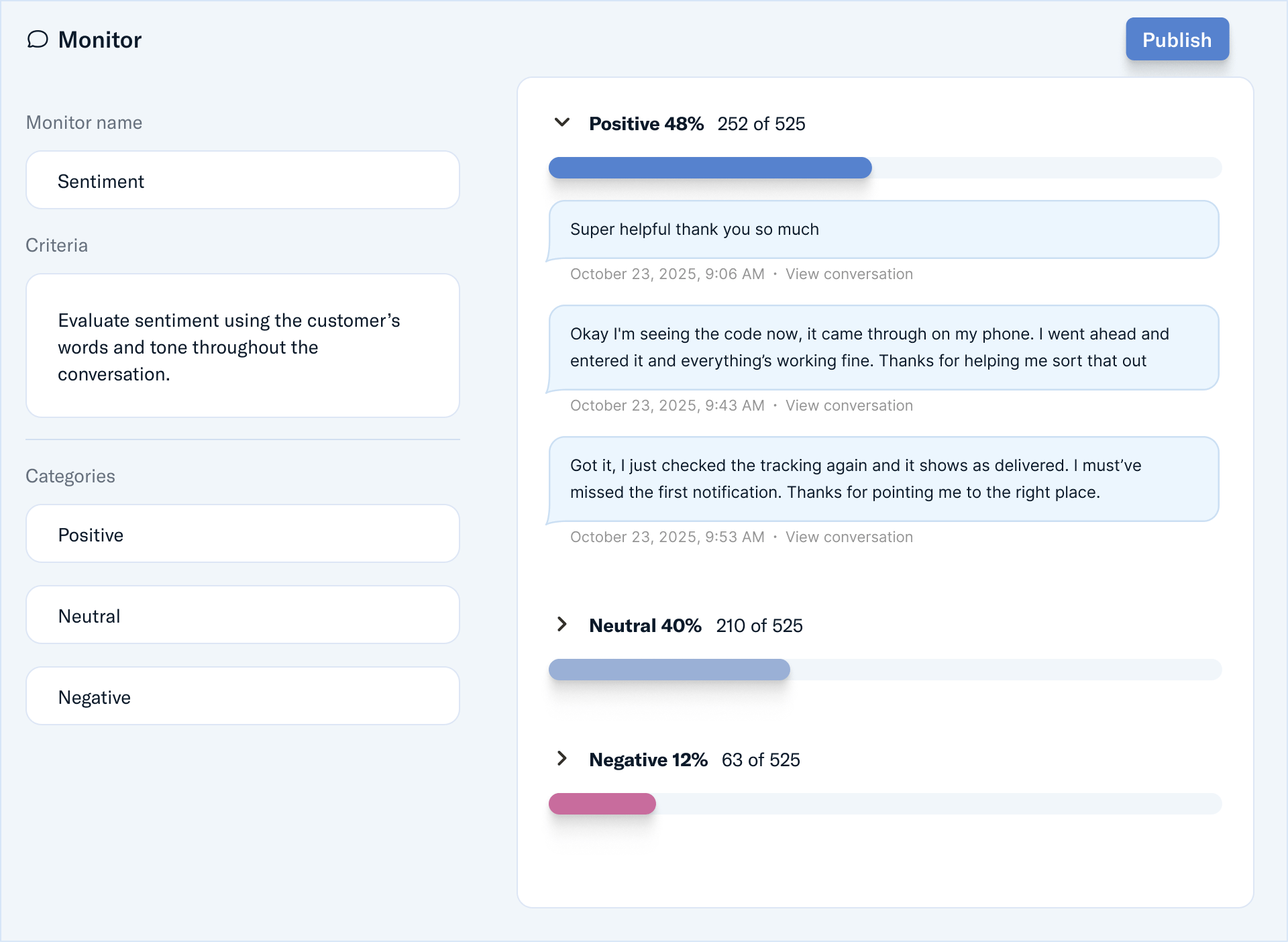
In addition to default monitors, teams can create custom monitors to measure what matters to their business. For example, they can flag whether a conversation contained a critical issue, track moments of customer frustration, or confirm that responses reflected their brand voice.
As monitors detect patterns or potential opportunities for improvement, they point teams straight to the exact conversations behind their advice. Every flagged conversation links directly to its transcript, so teams can see the context, tone, and outcome in a single view. From there, they can leave feedback, retrain behaviors, or create new monitors in just a few clicks — closing the loop between detection and improvement.
Over time, this creates a continuous feedback loop: every conversation contributes to better performance, better brand alignment, and higher customer confidence.
Reliability built in
Supervisors keep agents on track in every interaction — and monitors allow customer experience teams to continuously observe performance and refine their agents so nothing falls through the cracks. Together, they don’t just inspire confidence — they ensure that customer experience teams can measure it too.


