Preserving agent behavior while serving LLMs reliably
Traditional software reliability was largely about keeping systems online. If a server failed, traffic shifted elsewhere and the application continued to run.
With AI agents, reliability is more nuanced. A single agent’s behavior emerges from multiple LLMs working together across distinct inference tasks. Those tasks, like classification, tool calling, and response generation, are each powered by the model best suited for that specific job (see Constellation of Models).
That model-level precision raises a new reliability challenge: preserving consistent agent behavior while adapting to provider instability. This post breaks down the infrastructure we’ve built to keep availability high, without impacting the quality of the agent.
The serving problem: multi-provider reality, single-behavior expectation
LLMs are typically available through multiple service providers. For example, a model like GPT may be accessible through OpenAI’s infrastructure as well as a cloud-hosted deployment such as Azure. Each has its own capacity limits and rate-limiting behavior.
In practice, disruptions rarely appear as clean, uniform outages. Instead, we observe fluctuating rate limits, uneven capacity across regions, routing instability when traffic shifts too quickly, and periods when demand temporarily exceeds total available capacity.
When an inference task silently switches to a different model because a provider is constrained, the agent's decision-making can change. In such cases, simple failover isn't enough.
Serving agents reliably requires solving two separate problems: reacting to provider instability and protecting the model choices that define how the agent behaves. We address this with two complementary layers:
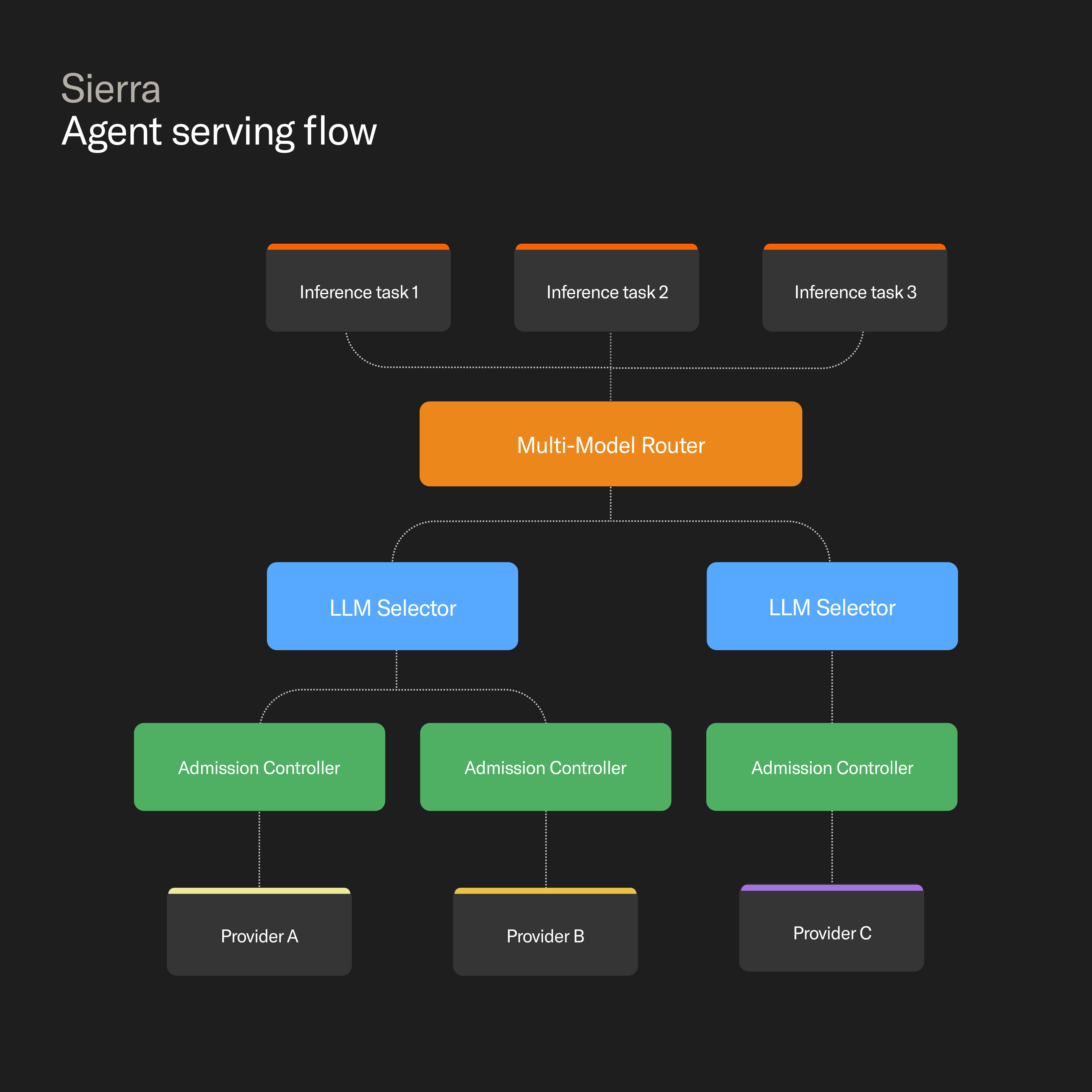
- A Multi-Model Router (MMR) that enforces the ordered list of models defined for each task and manages controlled fallback when the primary model is unavailable.
- A congestion-aware provider selector that dynamically distributes traffic for a given model across providers and uses congestion control to adapt to rate limits and outages.
The Multi-Model Router: automatic failover without changing agent behavior
The Multi-Model Router (MMR) enforces the prioritized list of models defined by the Sierra Agent SDK for each inference task.
For every task, MMR selects a model based on:
- The task-level model ordering defined by the Sierra Agent SDK.
- Real-time health and admission signals from the congestion-aware provider selector.
Under normal conditions, MMR selects the preferred model for a task. When that model becomes constrained, it evaluates whether fallback is permitted and, if so, selects the next pre-validated alternative in the priority list.
There are also cases where fallback is not appropriate. For example:
- When a task requires functionality available only through a specific model.
- When a user-visible streaming response has already begun and switching models could introduce tone or consistency discontinuities.
In these cases, MMR will not switch to an alternative model if doing so would negatively impact agent behavior.
Congestion-aware provider selector: detecting outages and rate limiting
The congestion-aware provider selector is responsible for maintaining stability at the provider layer when facing fluctuating capacity and rate limits.
Without congestion control, multi-provider routing can easily devolve into oscillation, especially under rate limiting conditions. For example:
- Provider A returns 429s → mark A unhealthy → shift traffic to B → overload B
- Load on A drops → mark A healthy → shift traffic back to A
- Repeat
This loop shifts overload between providers and destabilizes routing. To prevent this, we introduced an admission controller.
The admission controller limits how much traffic a constrained provider can receive by maintaining a dynamic admission score using additive increase / multiplicative decrease (AIMD), similar to TCP congestion control:
- Each candidate starts with a token budget.
- On rate limiting, the budget is multiplied by a backoff factor.
- On success, tokens are added back to gradually ramp traffic.
This smooths traffic shifts and avoids unnecessary failovers while maintaining efficient use of preferred models.
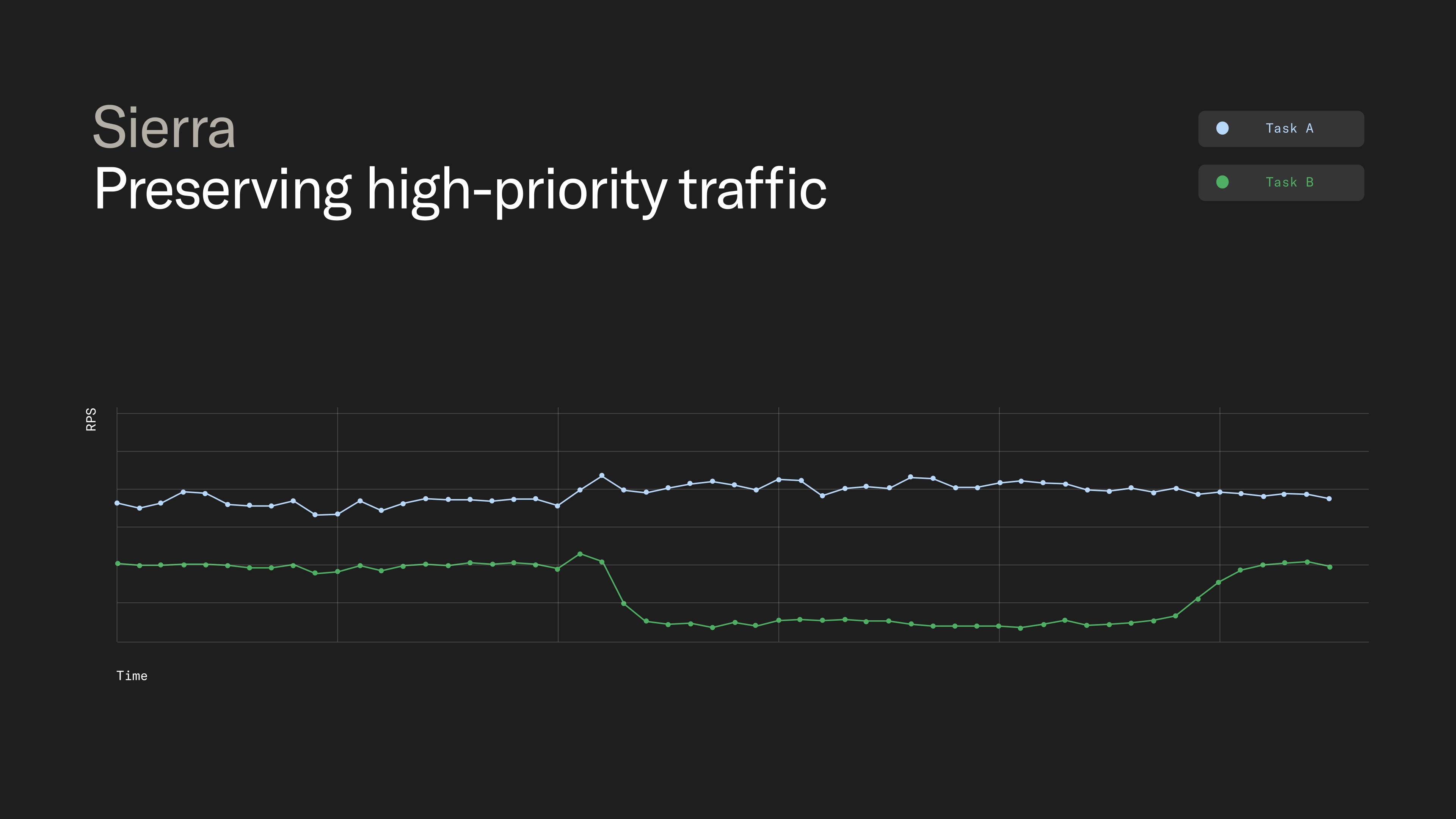
When traffic must be reduced, we attach a priority score to each request and shed lower-priority traffic first. This signals back to the MMR, which may retry against another model if appropriate. High-priority requests are preserved, while lower-priority traffic degrades gracefully.
By stabilizing provider traffic, we reduce the likelihood that temporary infrastructure issues alter the models serving each task — and therefore the agent’s behavior. Because this mechanism adapts dynamically, we don’t rely on rigid quota limits or heavy workload isolation to maintain stability.
Resilience without compromise
As AI agents become more complex, resilience can’t stop at uptime. It must extend to behavior. By separating model intent from provider adaptation, we ensure that agents remain stable under normal operation and degrade only in controlled, intentional ways when constraints demand it.
For teams building on Sierra, this means infrastructure instability never becomes visible as inconsistent agent behavior. The infrastructure beneath the agent may shift in real time, but the agent behavior users experience should not.


