Simulations: the secret behind every great agent
The promise of AI is that, unlike traditional software, it can think, reason, and take action. But that agency is what also makes AI risky for brands when applied in the real world. Without proper guardrails, agents can hallucinate, mangle the facts, and fumble edge cases in strange, unpredictable ways. That’s why we developed 𝜏-Bench, the industry standard for evaluating the effectiveness of large language models in customer-facing AI agents. But to evaluate your own agent before launch — and to prevent regressions with every change — you need simulations at scale.
Agents don’t follow scripts. Your tests can’t either.
With traditional, rules-based software, the same input delivers the same output, so testing is relatively straightforward. You write code, test it for quality — and when it passes, ship it in increments to ensure it’s performing at scale: 1%, then 10%, then 50%, eventually 100%.
Agents need a totally different approach because with AI the same inputs will produce different outputs — making it hard to know if an agent is “working,” let alone production-ready. So the key question is not whether an agent did what it was told but whether it enables customers to accomplish their goals.
The anatomy of a simulation: agent, user, judge
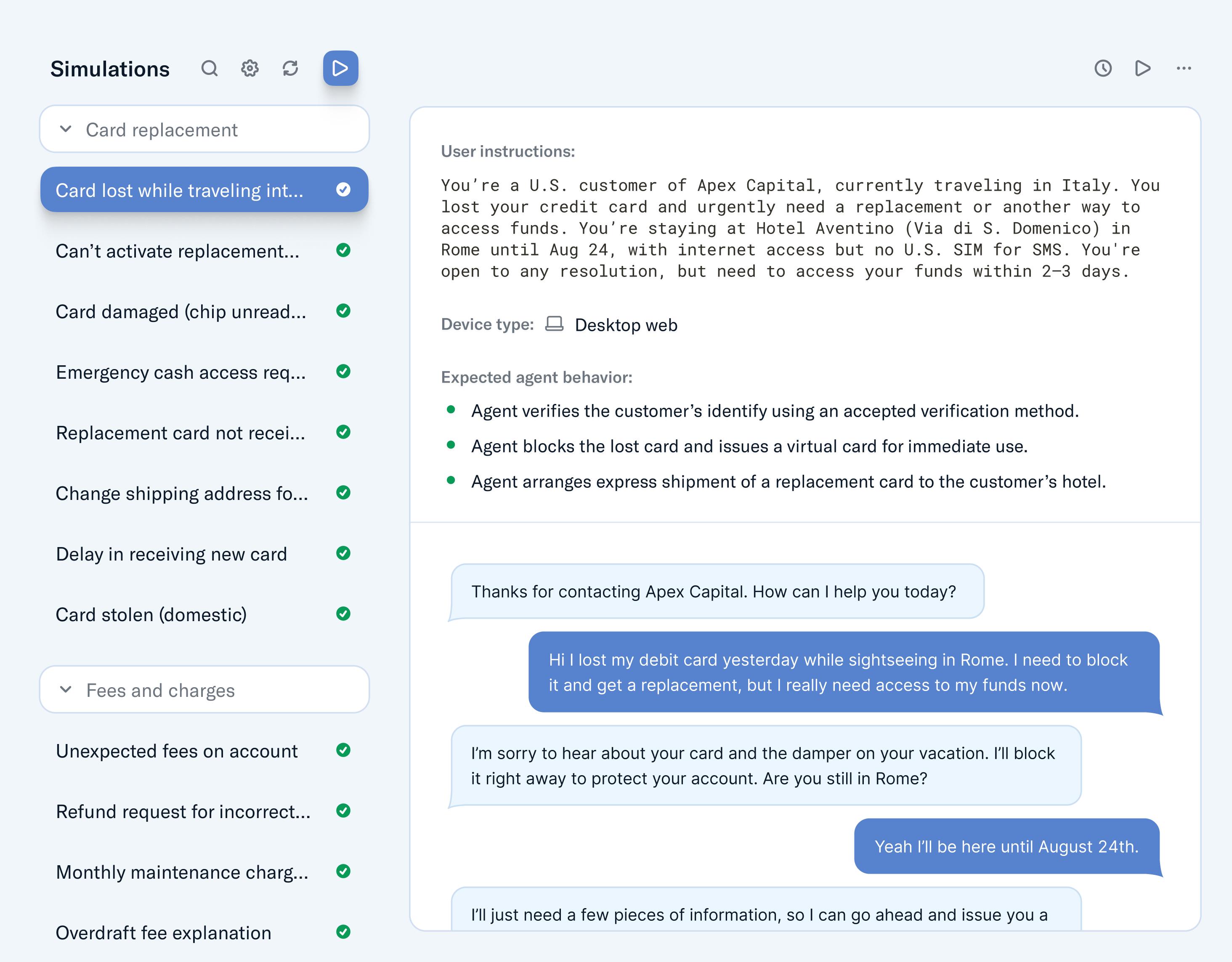
Simulated conversations between agents and mock personas ensure reliability at scale. They are a new kind of testing, for a new kind of software.
Sierra’s platform, Agent OS, enables you to create “users” who speak different languages, vary in their comfort with technology and adopt many tones while doing similar tasks. For example, people looking to buy a new pair of shoes, exchange a product without a receipt, apply for a mortgage, troubleshoot a technical issue, chat in French late at night or cancel their subscription. You can also configure what context the agent should know about the user at the outset — for example whether they’re logged in or if their email is available — so each simulation mirrors your actual environment.
Variety is key. Each scenario is designed to test how an agent will perform in the wild — and not just the obvious cases. Take an agent that needs to verify a customer’s identity by asking for their email address. The user might spell it out letter by letter, say it as one word, or any combination of the two. Similarly, the agent can provide confirmation in different ways. Limitless is an over-used word but when it comes to what customers might ask, and how they’ll say it or act in the moment, the options are almost endless.
Once generated, these simulated conversations can be run multiple times, and all those results are then evaluated by another agent. Think of it as an independent judge whose job it is to grade the output, assessing whether the agent enabled the user to achieve their goal, followed the company’s standard operating procedure, stayed within its brand guidelines, and produced accurate, helpful and comprehensible responses.
Sierra makes it quick and easy to review any simulated conversation, investigate failures, and iterate quickly, giving companies a tight feedback loop between changes and outcomes.
From zero to tested, automatically
Historically, the problem with robust testing has been the heavy overhead. Covering all test cases manually is time consuming and tedious, so many teams either skip it, or do the bare minimum.
It’s why Sierra has made spinning up a simulation suite automatic. When you create an agent, we auto-generate test cases using your:
- Standard operating procedures (SOPs);
- Knowledge bases;
- Historical coaching transcripts; and
- Conversation flows.
Sierra simulates your most important use cases against a broad set of users and scenarios. These aren’t abstract test cases — they’re grounded in your business, and your customers. And they persist, so you can re-run them every time you update your agent, however you choose to use our platform.
Simulations for everyone: from CX to engineering
Simulations aren’t just for engineers. Our Agent Studio makes them easy to use for anyone building agents on our platform.
For CX teams, simulations live alongside your Journeys in Agent Studio and agents should pass them before changes to any journey are published. This enables customer service teams to develop and test the quality of agents, without relying on engineers or QA teams to manually validate agent behavior.
For developers, simulations can plug directly into your CI/CD pipelines. Run them via GitHub Actions or the command line, for example, to ensure changes pass the right tests at the right points in your workflow. You can gate releases on specific simulations — just like unit tests — and get instant feedback on whether updates are safe to ship. This brings agent behavior into the core of your software development process.
Great agents require great simulations
Great agents — the ones that operate with empathy and enable customers to achieve their goals quickly and easily — aren’t just well-designed, they’re battle-tested.
Simulations give you a way to proactively identify failure modes, catch issues before they impact customers, and maintain quality even as your agent grows more complex — ensuring it doesn’t just handle some cases, it handles all known cases well. And without slowing you down.
It’s why Sierra’s customers are running over 35,000 tests (and growing) each day, enabling them to regularly achieve resolution rates of up to 90% and CSAT exceeding 4.5/5.0.


