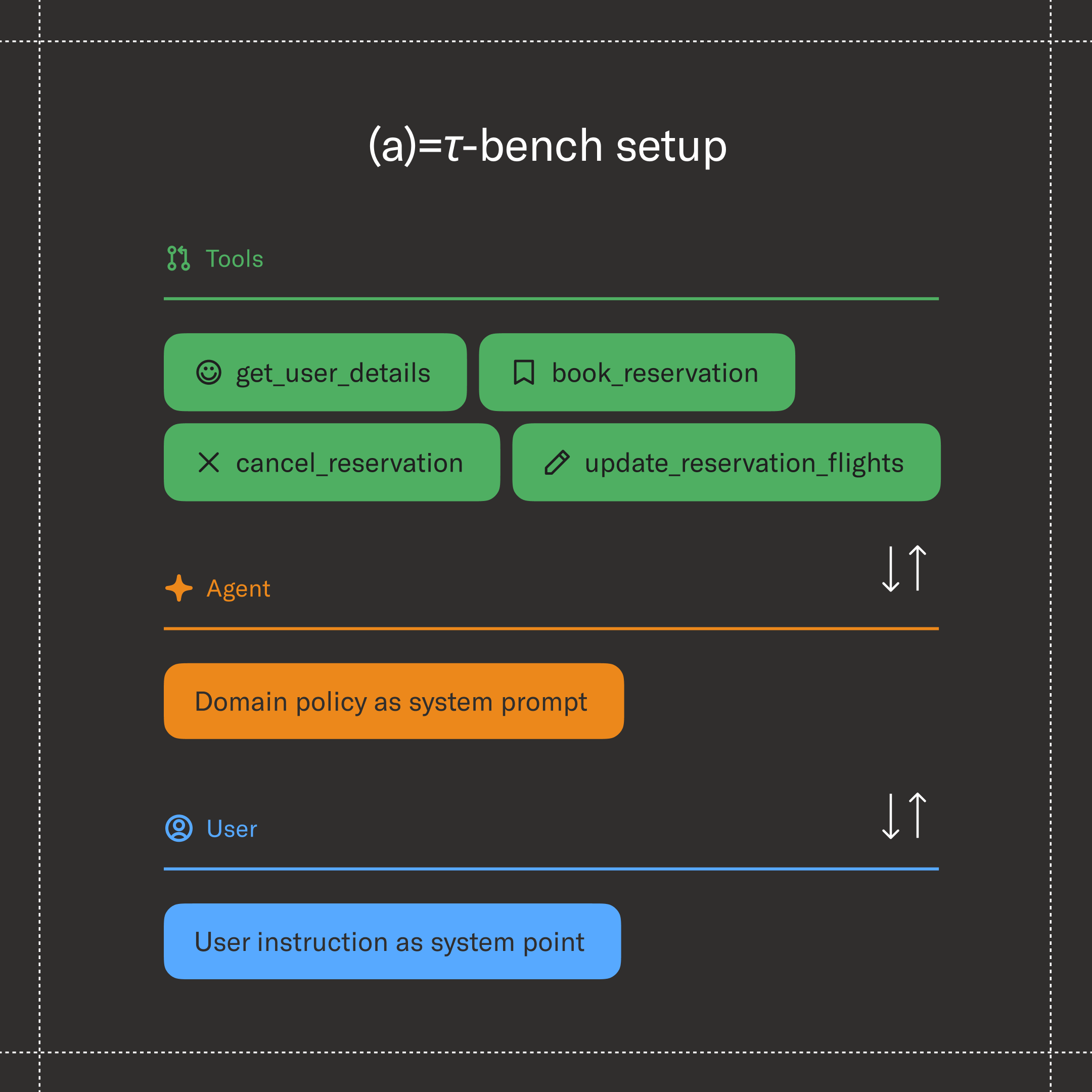
𝜏³-Bench: Advancing agent benchmarking to knowledge and voice
Since launching in June 2024, 𝜏-Bench has become the de facto standard for researchers, model builders, and enterprises using AI. It tests for something that’s easy to demo and hard to measure: whether a model can reliably help someone complete a task from beginning to end.
Today, we’re releasing 𝜏³-Bench, expanding the benchmark in several important ways:
- 𝜏-Knowledge tests whether agents can operate over large collections of internal company documents spread across systems and formats;
- 𝜏-Voice evaluates agents built for live voice conversations; and
- We’ve also incorporated fixes contributed by the 𝜏-Bench community across existing 𝜏-Bench domains to improve evaluation accuracy.
Shaped by our experience building and deploying agents at Sierra, these extensions point toward what we see as the next frontiers — and give the community a shared way to measure progress against them.
𝜏-Knowledge: evaluating agents over messy, evolving knowledge bases
Most agent benchmarks hand the model everything it needs upfront. But in the real world, agents need to navigate many different company documents to succeed: internal policy manuals, product catalogs, and standard operating procedures. This information is unstructured, ever-changing, spread across sources, and full of internal jargon — making simple search unreliable.
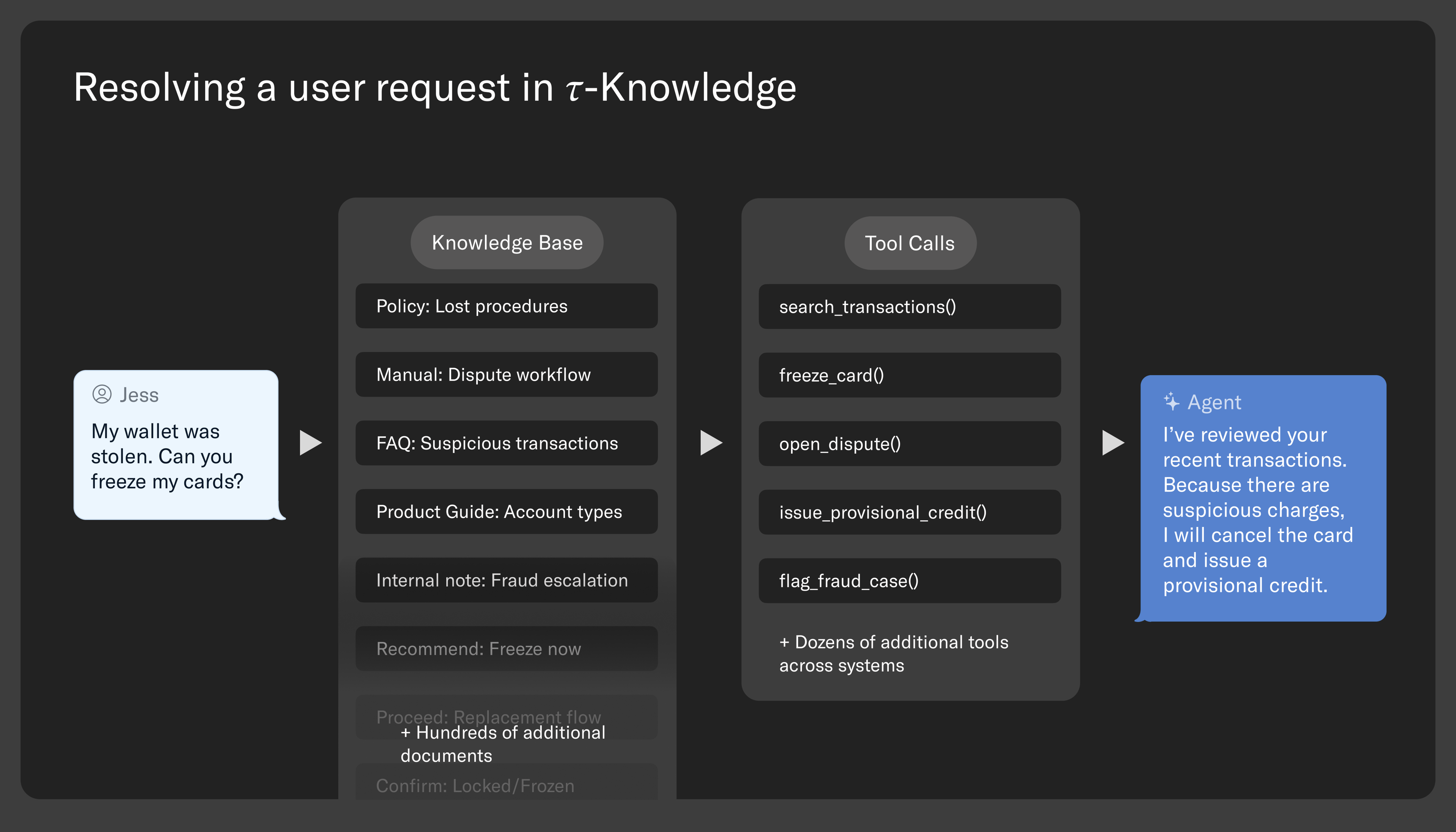
To test this, 𝜏-Knowledge introduces 𝜏-Banking, a fintech-inspired customer support domain built around a realistic knowledge base of 698 documents across 21 product categories (~195K tokens). Tasks require agents to search this corpus, reason over what they find, and execute multi-step tool calls — often identifying tools referenced only in documentation rather than explicitly listed. For example, resolving a disputed transaction might require the agent to locate the correct dispute policy across multiple documents, infer the appropriate provisional credit workflow, freeze the card, open the dispute, and issue a temporary credit — all in the correct order.
𝜏-Knowledge does not assume a single method for finding information. It supports keyword search, embedding-based retrieval, long-context approaches where large portions of the knowledge base are provided directly to the model, and even direct file exploration through terminal-style commands. This allows it to evaluate new retrieval methods, not just standard semantic search. Task success is measured based on whether the correct updates are made to the simulated backend database — for example, whether a dispute is opened, a card is frozen, or a credit is issued — rather than on how polished or convincing the conversation sounds.
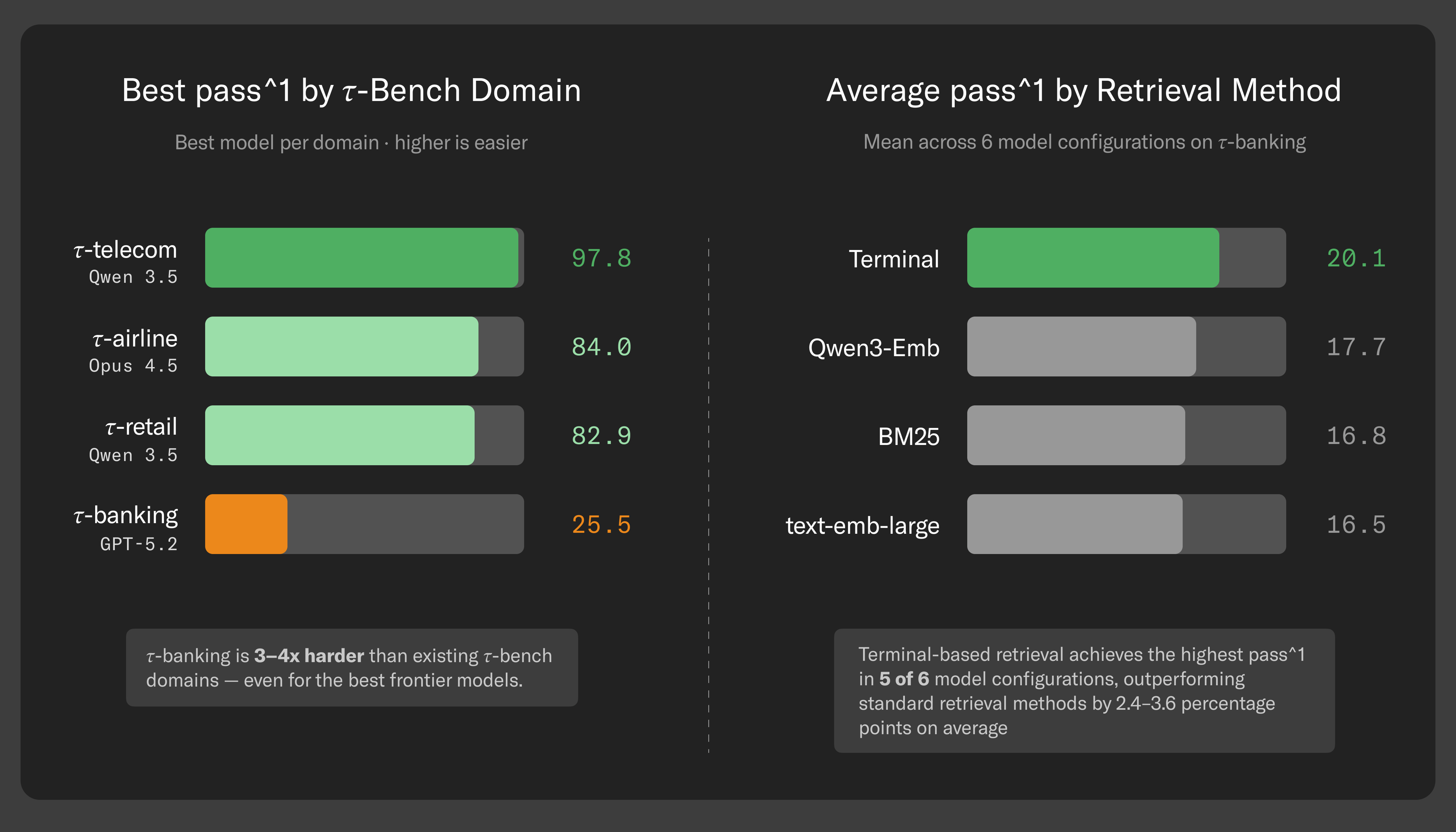
The results are striking. The best frontier model — GPT-5.2 with high reasoning — succeeds on about 25% of tasks. Even when we provide the exact documents needed to complete the task, performance rises to just 40%. This suggests the bottleneck isn’t only finding the right information — it’s understanding it, drawing the correct conclusions, and executing the required actions.
We also see meaningful differences depending on how the knowledge base is accessed. Models perform better when given flexible, freeform access to a knowledge base (e.g., via a terminal) than when restricted to traditional semantic search. But that added flexibility comes at a cost: agents can respond significantly faster when using more structured retrieval methods.
These patterns show up even more clearly when we look at reliability and efficiency. Some models reach similar accuracy but take nine times longer to do so, while others that score lower overall are much more consistent across repeated trials. In human-facing deployments, that efficiency gap matters: agents that need more turns, more searches, and more tool calls not only cost more, but also feel slower and less trustworthy to the user.
Paper | Leaderboard | Tau-Knowledge Report
𝜏-Voice: evaluating agents in realistic voice conditions
Voice is quickly becoming the default way we interact with agents, but natural conversation brings a completely different set of challenges than text-based chat. You interrupt. You say “uh-huh” while the other person is still speaking. You change your mind mid-sentence.
Real conversation is full-duplex — both sides speaking and listening at once — and it's messy. Voice agents need to handle all of this while still completing real tasks: looking up orders, updating accounts, booking flights. Today's benchmarks test these skills in isolation. None measure whether voice agents can do both at once, under realistic conditions.
𝜏-Voice extends 𝜏-Bench to live voice interactions with complex turn-taking dynamics. Rather than clean audio in a quiet room, it simulates the kind of call an agent would actually receive: a user with an accent calling from a noisy coffee shop, on a spotty connection, over a compressed phone line. The failures are predictable but hard to fix. A user spells out a confirmation code and the agent mishears one letter — authentication fails. The user says "yes" to confirm a cancellation, but it's lost in background noise, so the agent asks again, and again. A network dip drops a few frames mid-sentence and the agent hallucinates the rest.
Turn-taking is the other half of the challenge. Our simulated user doesn't passively wait for the agent to finish. They cut in when they've heard enough and push ahead when the agent hesitates — all controlled by configurable parameters for how patient, how interruptive, or how silence-averse the caller is.
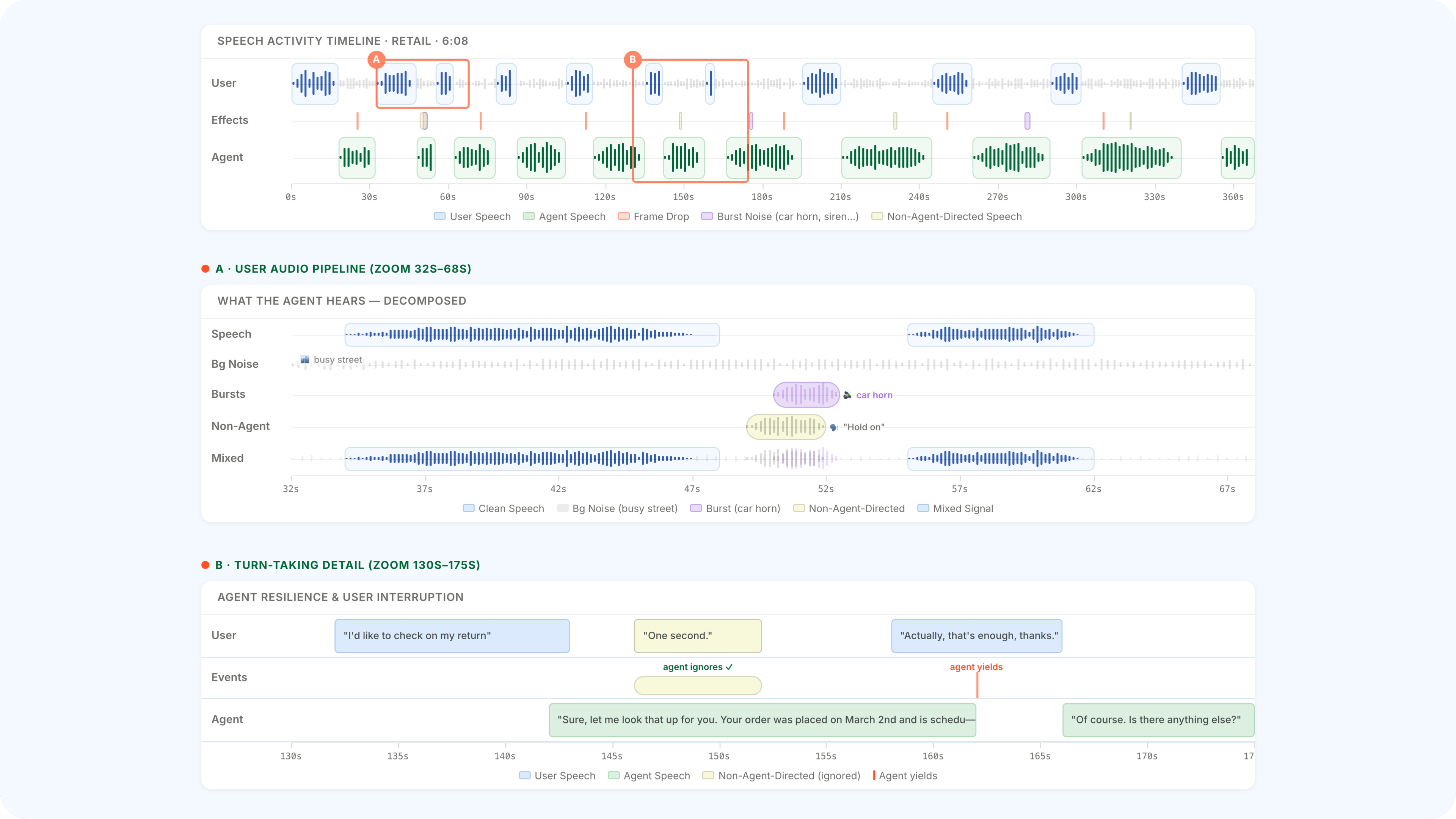
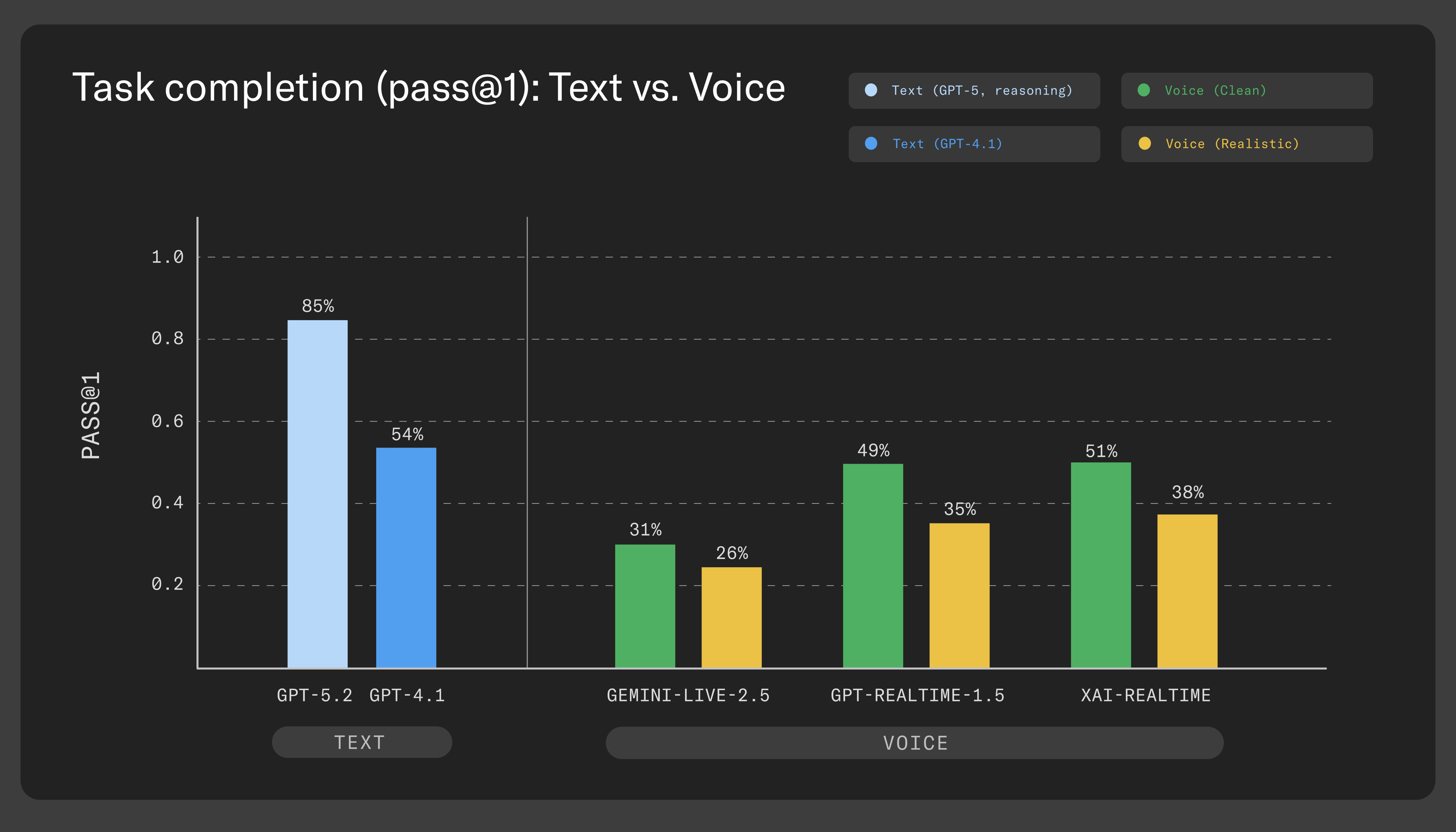
We benchmarked three closely matched voice providers — OpenAI Realtime, Google Gemini Live, and xAI Grok Voice. The headline comparison is non‑reasoning text models versus voice agents in realistic conditions: under ideal conditions (no interruptions or audio effects) the best voice agents get close to non‑reasoning text models (~54% vs 31–51% clean voice), but once you introduce realistic audio and turn‑taking the gap widens substantially (~54% vs 26–38% realistic voice). Text agents with reasoning reach ~85%, and closing that gap will require agents that can reason through multi-step tasks while sustaining a fluid conversation, not just think longer before replying.
Where do things go wrong? The failure patterns are consistent across providers: authentication is the bottleneck — once the agent mishears a name or email, everything downstream fails. Beyond transcription, agents lose track of multi-step requests, completing one part of a task but forgetting the rest, or never recover from repeated failures.
We're releasing 𝜏-Voice not just as a benchmark, but as a platform for evaluating voice agents — because the gap between lab conditions and real calls is where the hardest problems live.
Paper | Leaderboard | Examples
Strengthening the core 𝜏-Bench domains
Alongside the new domains, we’ve incorporated a broad set of community-driven fixes to the original 𝜏-Bench airline, retail, and telecom tasks. Many of these revisions came directly from external audits — especially the 𝜏²-Bench Verified effort from Amazon — as well as community pull requests, including several from Anthropic. These updates resolve incorrect expected actions and ambiguities, and tighten evaluation criteria to better reflect real policy and system behavior. For more, see the detailed notes.
Evaluation benchmarks that match the reality of agents today
As agents become an everyday part of the customer experience, benchmarks must measure more than clean demos. 𝜏³-Bench tests agents under the real-world conditions where they are most likely to break — not just to expose their flaws, but to help the community build agents with real-world reliability.