𝜏-voice: benchmarking real-time voice agents on real-world tasks
Voice is rapidly becoming a primary interface for agentic systems, yet today's evaluation landscape splits voice agents in half.
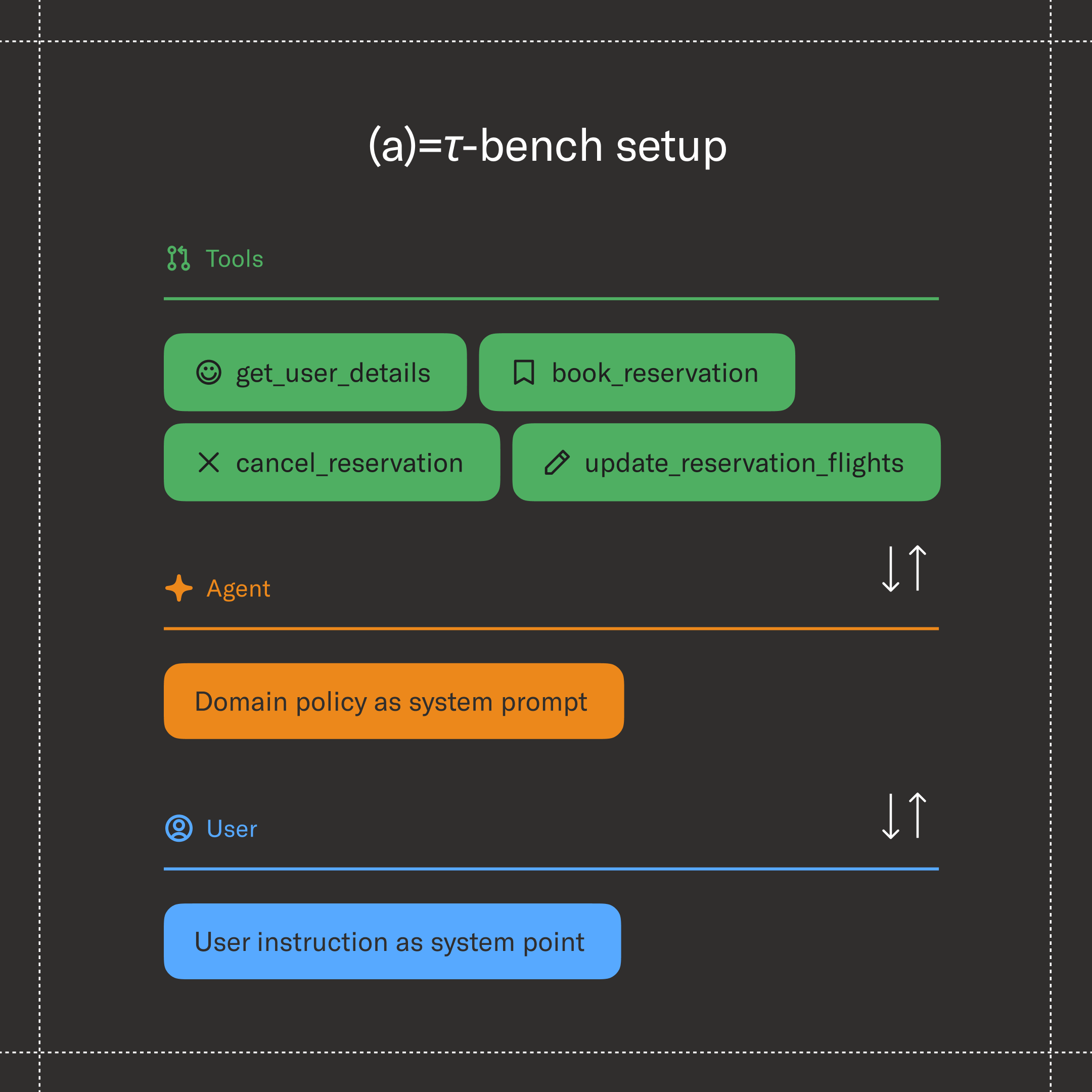
Audio benchmarks measure conversational dynamics — does the model interrupt politely, yield gracefully, recognize a backchannel, sound natural under noise? But they rarely check whether the agent actually solved the caller's problem. On the other hand, task-completion benchmarks are well established in the text domain (𝜏-bench among them): they rigorously verify that the agent called the right tool, followed the right policy, and changed the database the right way — but they assume a clean text channel and never expose the agent to real audio.
The risk is shipping voice agents that hold a charming conversation while quietly failing the underlying task — or, conversely, agents that nail the task in writing but fall apart the moment a real caller starts talking over them. For example:
A customer calls to make changes to their account. Background noise from a busy street and an unfamiliar accent push the speech recognizer off, and authentication fails.
- Does the agent ask them to spell their name?
- If they spell it, does the agent transcribe it correctly?
- If so, does it actually fix the failed authentication call — or does it lose track of the corrections spread across three turns?
None of the standard benchmarks would catch a failure like this because each step looks fine in isolation. Measuring both dimensions together — task completion and conversational dynamics, on the same call, under realistic audio — is what lets us see these integrated failures, quantify how much of an agent's text capability survives the move to voice, and surface regressions for the people most affected: speakers with non-standard accents, callers from noisy environments, users on degraded connections. Robustness to realistic audio conditions is an accessibility issue.
This is also a timely thing to measure. Audio-native models — systems that ingest and produce speech end-to-end without an intermediate transcript — are the next frontier of agentic AI. They’re generally available from OpenAI, Google, and xAI, and are improving fast. A benchmark that’s sensitive to both task and conversation gives us a way to track exactly how quickly that frontier is moving.
Introducing 𝜏-voice
𝜏-voice is the first benchmark to combine three things that have up until now been evaluated in isolation:
- Verifiable, grounded tasks shared with the text benchmark: 278 customer service tasks inherited from 𝜏-bench, scored deterministically against the final database state. The tasks, tools, policy documents, and evaluator are byte-for-byte identical to those used by text agents on the 𝜏-bench leaderboard. That means the voice numbers in this post can be compared directly against a text agent on the same task — voice vs. text, on the exact same problem, no apples-to-oranges caveat.
- Live, simultaneous speech: The user and agent can speak at the same time, with overlap, interruptions, and backchannels — the full-duplex regime, in contrast to the half-duplex, strictly turn-based setting of text agents. A tick-based orchestrator coordinates 200 ms audio chunks in both directions, lets the agent be interrupted mid-sentence, and gives us precise, repeatable control over turn-taking timing.
- Realistic, controllable audio: A voice user simulator that synthesizes caller speech with diverse personas, mixes in environmental noise, applies telephony compression, drops frames, and decides turn-by-turn whether to interrupt, yield, or backchannel.
One implementation note that’s worth flagging: The major voice provider APIs (OpenAI Realtime, Gemini Live, xAI Grok) don't require a simulated call to play out in real-time. We can run a session at whatever pace we want without changing what the agent hears, which means the user simulator isn't held to a realtime latency or token budget — we're free to pick whatever text LLM works best for simulating the caller (GPT-4.1 in our experiments). With this approach, we don’t have to choose between a strong simulator, precise control over turn-taking, and reproducible runs.
The voice user simulator, end to end
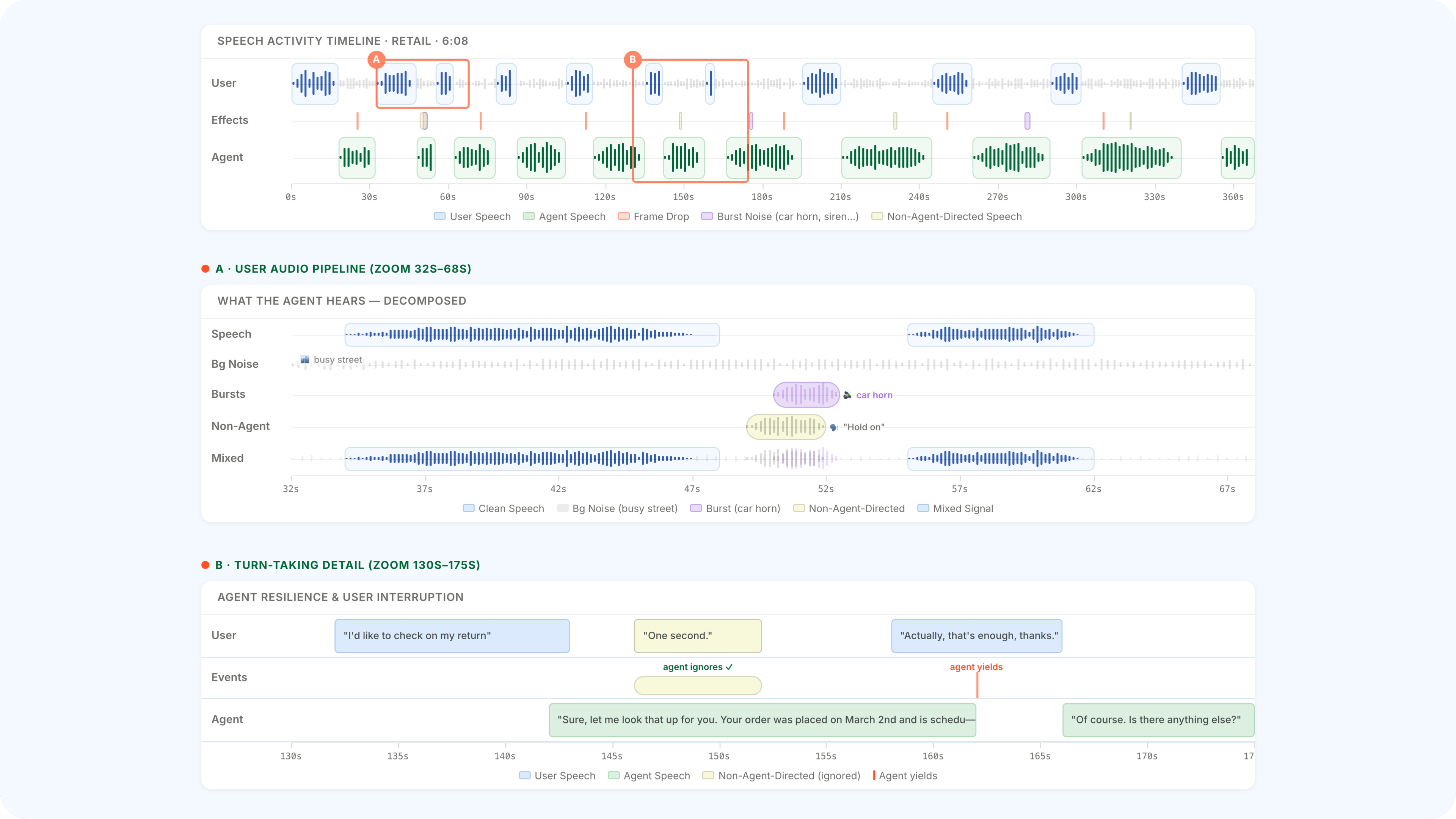
At each tick, the simulator does four things in sequence: it generates the next caller utterance as text, synthesizes it through a voice persona, mixes the synthesized speech with environmental audio (background noise, vocal tics, non-directed speech), and applies channel degradation (G.711 µ-law compression at 8 kHz, dynamic muffling, frame drops via a Gilbert–Elliott model). A separate LLM-driven turn-taking policy, evaluated every two seconds, decides whether to interrupt, yield, or backchannel.
Voice models are improving fast — really fast
Because 𝜏-voice inherits its tasks, tools, and evaluator from 𝜏-bench, voice numbers can be plotted directly on the same axis as text. The chart below is the 𝜏-voice progress timeline — the same view rendered by the live leaderboard's Progress over time panel — overlaid with two text reference lines: the current text reasoning ceiling (~85% pass@1, Gemini 3 Pro / GPT-5.2 / Claude Opus 4.5), and a strong non-reasoning text baseline (54%, GPT-4.1).
In about eight months, the voice frontier has moved from 30% (OpenAI's gpt-realtime-1.0, Aug 2025) to 67% (xAI's grok-voice-think-fast-1.0, Apr 2026), crossing the non-reasoning text line and closing most of the way to the reasoning ceiling. The biggest single move is the most recent one: a +29 pp jump in roughly two months driven by xAI's reasoning-enabled audio-native model. The pattern is familiar from text: adding explicit reasoning to the audio-native model unlocks a step change in tool-use reliability. Voice has gone from retaining roughly 45% of text capability when the paper was written, to ~79% today, all with the same domains and evaluator, and no asterisks.
To explore the full leaderboard — including per-domain breakdowns, custom submissions, the same Progress-over-time panel, and the underlying trajectories — jump straight to the 𝜏-voice ranking (or the 𝜏-bench text ranking for direct comparison). We've worked with every major audio-native provider so far. The chart above will keep moving.
What's actually going wrong
Before zooming into the failures themselves, it helps to see how each provider's pass@1 changes when we move from Clean (single persona, no acoustic effects, strict turn-taking) to Realistic (diverse personas, environmental noise, free-form turn-taking) on the paper-era models — the absolute drop varies, but every provider takes a hit.
Knowing each provider takes a hit is one thing. Knowing which mistakes drive the hit is another. Two annotators labelled every failed simulation in two analysis cohorts — Voice-Fragile (tasks the text models pass but voice-Clean models fail) and Noise-Fragile (tasks voice-Clean passes but voice-Realistic fails) — tagging both the source and type of the first critical error.
The four failure modes that matter most
How much does each ingredient of "realistic" compound failures?
To quantify how much each part of "realistic" contributes to the failure modes above, we ran ablations on the retail domain — adding background noise, diverse accents, and turn-taking dynamics one factor at a time, on top of an otherwise clean condition.
Listen to real 𝜏-voice failures. Same task, clean vs realistic conditions, side by side — with an annotated, playable speech-activity timeline. Open audio examples →
If you build a voice agent or run a voice platform, implement an adapter and reach out — we'd love to add your system to the leaderboard.
What 𝜏-voice does not measure (yet)
We are deliberate about scope. There are a few things 𝜏-voice does simplify, and plans for what’s next:
- English only, TTS-mediated accents: Diverse accents are induced by ElevenLabs personas, not by recorded human speakers. This is enough to surface large per-provider gaps, but the absolute numbers should be read as indicative rather than definitive. We are scoping 𝜏-voice strictly to English and TTS-driven personas. Broader language and recorded-speaker coverage is left to future benchmarks.
- Transcript injection on the user side: The user simulator reads the agent's transcript directly rather than transcribing the agent's audio. In our manual review, agent speech was intelligible in 100% of 91 sampled simulations — agent-side ASR is a non-issue today — but as voice models get more expressive this assumption may need to be revisited.
- No agent speech-quality scoring: We measure what the agent says (and whether it took the right action), not how naturally it speaks. Adding tone, naturalness, and user-perception metrics is straightforward future work.
- Cascaded baselines: The framework supports cascaded ASR→LLM→TTS pipelines as well as audio-native models, but we have not yet published a head-to-head comparison. This is the cleanest way to isolate "voice modality" from "model architecture" effects.
Open, reproducible, and yours to build on
𝜏-voice is part of the broader 𝜏-bench framework. Tasks, environment, voice user simulator, audio effects, turn-taking policy, and evaluation are all open source. Every result here is reproducible from a fixed seed (LLM stochasticity aside), every audio sample on the examples page comes from a real 𝜏-voice run, and every voice submission on the leaderboard ships with its trajectories so you can replay the conversations end-to-end.
The official voice personas are held out, but a one-command script generates equivalent ones via the same ElevenLabs Voice Design API, so external developers can iterate locally and expect improvements to carry over to the official eval.
If you train voice models, evaluate voice agents, or just want to understand where today's systems break down, we'd love your contributions — new audio-native providers, cascaded ASR→LLM→TTS baselines, and pull requests against the user simulator are all welcome.
Voice agents will be in production whether or not we measure them carefully. We'd rather measure them carefully.
For full details, see our paper, the code, and the leaderboard. The framework was built by Soham Ray, Keshav Dhandhania, and Victor Barres at Sierra, with Karthik Narasimhan at Princeton.