Voice AI is only as good as what it hears
When most people think about voice AI, they think about what the agent says. But before an agent can respond, it has to hear, and it turns out that’s one of the hardest problems in conversational AI.
Take someone calling their bank or insurance company to verify their identity. Their first name is "Caitlyn". It sounds simple enough — except there are at least four ways to spell the name: Caitlyn, Kaitlyn, Katelyn, or Caitlin. A support associate would glance at the account, check the spelling, and move on. A speech transcription model, by contrast, predicts the statistically most likely option from its training data, which may or may not be correct.
Name disambiguation is but one of several challenges agents face in trying to understand what a caller is saying. Another is recognizing specific technical terms, brand names, or industry jargon that rarely appear in the English-language data these models are trained on. A single misheard syllable can be the difference between success and failure, and at scale, these small transcription errors compound into systemic failure.
Transcription — the conversion of speech into text in real-time — is the foundation for every call. Yet most platforms treat it as a commodity: choose a provider, pipe in audio, and hope for the best.
At Sierra, we’ve built a transcription platform that dynamically routes across providers, incorporates a customer’s context, supports 70+ languages, and adapts to real-world variability, improving both agent effectiveness and customer satisfaction.
The problem with "good enough" transcription
Standard speech-to-text APIs perform well on standard American English in quiet environments. But real-world voice AI is much more complex.
To evaluate performance under these conditions, we built an internal benchmark using domain-specific customer service audio. Unlike typical benchmarks that are based on clean recordings in controlled environments, Sierra’s reflects the conditions agents actually operate in: short, choppy utterances, background noise, a wide range of accents, and multilingual conversations. This gives us a quantitative view of real-world performance and a foundation for improving it over time.
And unlike other conversations — where agents can infer intent from a “good enough” transcription — verification is binary: you need an exact match.
When both spellings sound the same, the model guesses. But that’s an easy case. For names from languages underrepresented in the training data, the model may not even produce a plausible transliteration. If context shifts mid-conversation, the challenge gets harder. For example, a caller who starts in English, switches to Spanish to spell their name, then slips back to English. Or an agent that needs to capture a French street name inside an otherwise English call.
Standard transcription pipelines process audio in isolation, without awareness of what the conversation is about or what the caller is likely to say next.
Multi-provider ensembling: triangulating toward the truth
No single transcription provider is great at everything. Accuracy varies by language, latency constraints, audio quality, and speaking style. Different models make different mistakes on the same audio.
Instead of picking one provider and managing its weaknesses, we built an ensembler that queries multiple providers in parallel and combines their outputs.
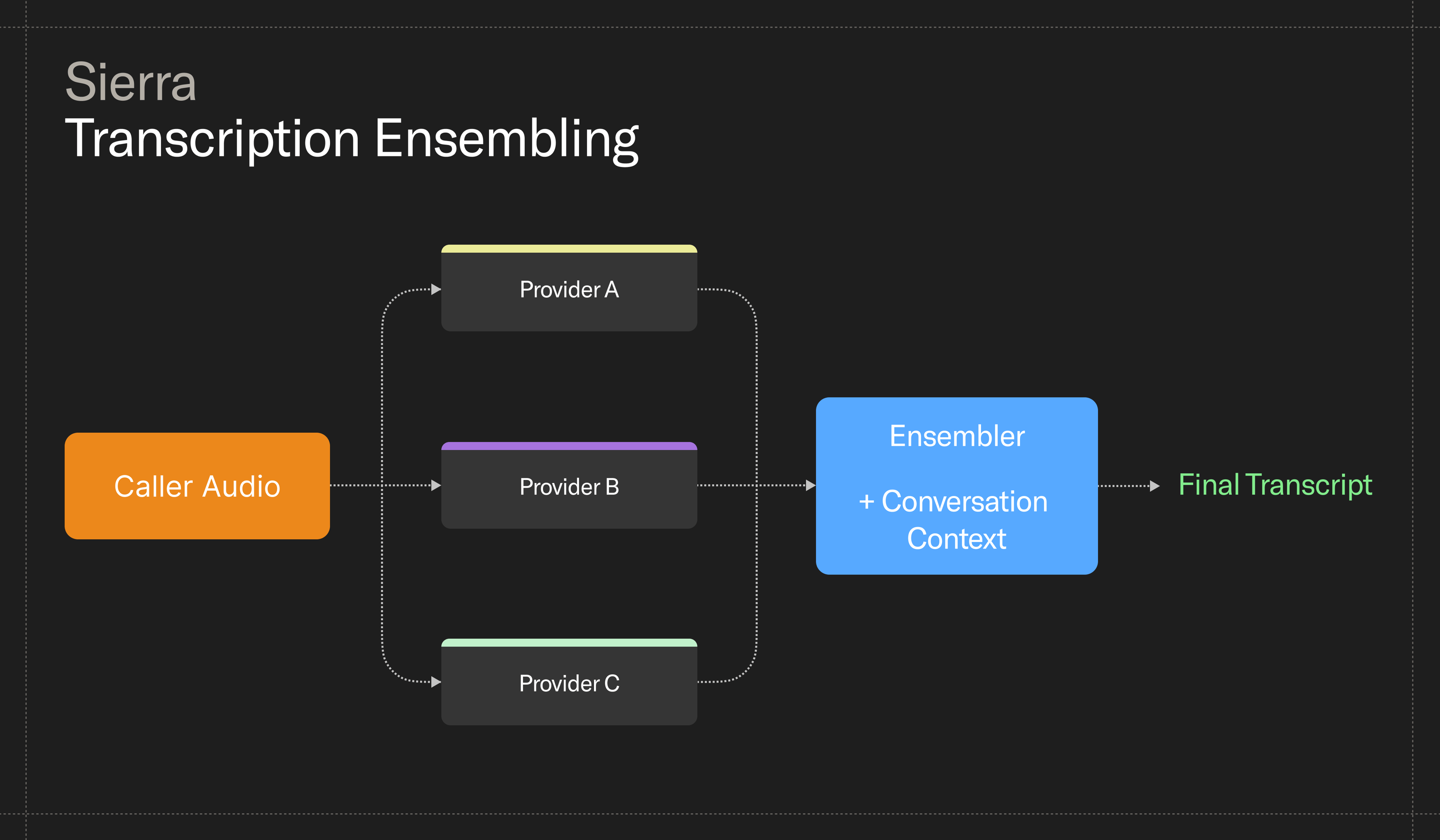
The ensembler doesn't pick the "best" result or go with majority vote. It applies custom logic to:
- Cross-reference outputs and identify where providers agree or diverge; and
- Incorporate signals from earlier turns in the conversation.
Running multiple providers also improves reliability. Speech APIs occasionally degrade or fail under load, and relying on a single provider can turn a transient outage into a broken customer interaction. By querying multiple transcription models in parallel, the system can continue operating even if one provider becomes unavailable.
On our internal benchmarks, we have found that ensembling can cut utterance error rate (how often an utterance has a meaning-changing error) by ~25% on average versus the best single provider, and by up to 37% in languages with more headroom for improving transcription.
Disagreement between models tells us something. By triangulating across providers and grounding in conversation history, we produce transcripts that are more reliable than any individual system alone. This is particularly powerful in edge conditions, where providers fail in different ways.
Context-aware transcription: collapsing the search space
Ensembling gets stronger when each provider has better information to work with. Our platform is injecting conversation context directly into the transcription process. When a voice agent asks a caller to verify their name, we already know what name we're expecting — it's in the customer record. When we ask for an address, we know the address on file. Rather than asking the transcription model to guess from the full space of possible utterances, we feed it context from the conversation.

For our financial services agents, context-aware transcription improved input verification rates by over 25% — translating directly into fewer callers needing to be transferred to a support associate to solve a problem the AI agent should easily have handled.
After extending context-aware transcription to all voice turns, Sierra voice agents have improved resolution rates by up to 1%, which translates to tens of thousands of resolutions a week, and reduced major transcription errors by up to 15%.
Seamless language switching
Sierra's transcription platform supports over 70 languages and dialects, from Danish to Tagalog to Cantonese. A caller in the United States speaks English but has a Spanish name and address. The agent needs English transcription for the general conversation, Spanish-aware transcription for the name and address, and then English again. Or a caller in Hong Kong starts in Cantonese, switches to English for a technical term, then back to Cantonese.
When the conversation language shifts, the system dynamically reconfigures the transcription pipeline — selecting a different ensemble of providers optimized for that language — without dropping audio or adding latency.
This matters for the many real-world conversations that don't stay neatly in one language. It also matters for global brands that serve customers across dozens of markets with a single platform.
Conversational recovery: asking when you can't hear
Sometimes the problem isn't the transcription model — it's the audio. The caller is in a noisy environment, their phone connection may be poor, or they may have spoken too quickly. No amount of ensembling or context injection will produce a reliable transcription from unintelligible audio.
In those cases, the best response is to ask for clarification, just as a human would. "I'm sorry, I didn't quite catch that. Could you spell your last name for me?" is a far better experience than confidently verifying the wrong name and sending the caller down the wrong path. Most voice AI systems process whatever the transcription model returns. Our platform enables graceful recovery instead of silent failure.
Why this matters
Voice AI is only as good as what it hears. The most advanced language model, the most carefully designed workflow, the most natural-sounding voice — none of these matter if an agent can't accurately understand what the caller is saying in the first place.
By building transcription as an intelligent, multi-provider platform, we've turned the weakest links in voice AI into infrastructure our agents can rely on to take action and recover gracefully when conditions are difficult.
For financial services companies, healthcare providers, and global brands that trust Sierra with their customer conversations, accuracy is a requirement. Our transcription platform ensures the conversation starts on solid ground.


